kNN — k近邻算法
K Nearest Neighbor,也称为k近邻算法 ,可以这样理解它:
- 先读出一堆分好类的数据点,每一个数据点在坐标轴上都有一个位置,标记他们的分类
- 归一化数据
- 计算我们要预测的数据 X 到每个数据点的距离,并且排序
- 选取与X点最近的K个点,确定哪个分类的出现次数最多,那么我们就预测这个数据 X 属于这个出现次数最多的分类
简单地说,k近邻算法采用测量不同特征值之间的距离方法进行分类。
优点:精度高、对异常值不敏感、无数据输入假定。
缺点:计算复杂度高、空间复杂度高。
适用数据范围:数值型和标称型。
类别分析
例:
导入包
1 | import numpy as np |
1 | # 获取数据 |
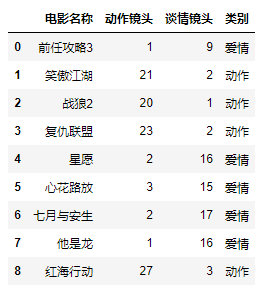
1 | # 获取特征集合和标签集合 |
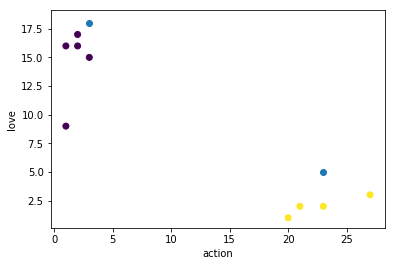
1 | # k值的取值范围 不大于样本集数量的平方根 |
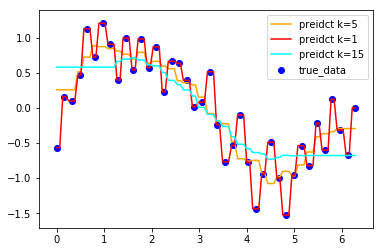
KNN处理回归
例:
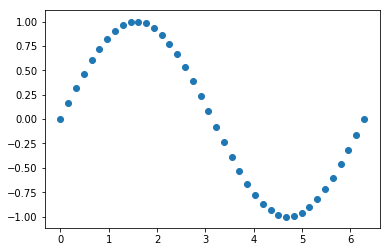
1 | import numpy as np |
1 | # 生成一组符合正弦分布的数据样本点,x就是样本,y样本标签 |
1 | # 创建噪音数据,模拟真实环境 |
1 | # 把噪音数据添加到样本标签中,查看包含噪声的数据分布情况 |
1 | # 分别训练三种不同k值的knn回归器,预测结果,查看预测情况 |