数据分析三剑客 numpy、 pandas、 matplotlib
NumPy
NumPy 是什么?
NumPy是Python中用于科学计算的基础包。它是一个Python库,提供多维数组对象,各种派生的对象(如掩码数组和矩阵),以及数组快速操作的各种各样的例程,包括数学、逻辑、图形操作,排序、选择、I/O、离散傅里叶变换、基本线性代数、基本统计操作,随机模拟以及其他。
NumPy包的核心是ndarray对象。它封装了均匀数据类型的n维数组,带有一些在编译过的代码中执行的操作。NumPy数组和Python标准列表有一些重要的差异:
- NumPy数组在创建时有固定的大小,不像Python列表(可动态增长)。改变一个ndarray的大小将创建一个新数组,并删除原有数组。
- NumPy数组中的元素都必须是相同的数据类型,从而具有相同的内存大小。但有个例外:(Python,包括NumPy)对象数组的元素大小是不同的。
- NumPy数组使大量数据上的高级数学运算和其他类型的操作变得容易。通常情况下,这样的操作可能比使用Python的内置列表效率更高,执行的代码更少。
- 越来越多的基于Python的科学和数学包使用NumPy数组;虽然它们通常支持Python列表作为输入,但他们会在处理之前将这些输入转换为NumPy数组,并总是输出NumPy数组。换句话说,为了高效使用许多(也许甚至是大多数)当今基于Python的科学/数学软件,只要知道如何使用Python的内置列表类型是不够的————你还需要知道如何使用NumPy数组。
Ndarray 对象
NumPy 中定义的最重要的对象是称为 ndarray 的 N 维数组类型。 它描述相同类型的元素集合。 可以使用基于零的索引访问集合中的项目。
ndarray中的每个元素在内存中使用相同大小的块。 ndarray中的每个元素是数据类型对象的对象(称为 dtype)。
创建ndarray
导入numpy库
1 | import numpy as np |
使用np.array()创建多维数组
参数为列表: np.array([1,2,3])
注意:
- numpy默认ndarray的所有元素的类型是相同的
- 如果传进来的列表中包含不同的类型,则统一为同一类型,优先级:str>float>int
1 | np.array([1,2,"3"]) |
使用np的常用函数(routines)创建
包含以下常见创建方法:
1、np.ones(shape, dtype=None, order=’C’)
功能:按照指定形状创建多维数组,并用1填充
参数:
shape 用于指定创建的多维数组的形状 可以传入2 或者 (2,3)
dtype 数据的类型 np.int8 np.float64
返回值:返沪创建好的多维数组数组
2、np.zeros(shape, dtype=float, order=’C’)
功能类似np.zeros只不过不是用1填充 而是用0填充
3、np.full(shape, fill_value, dtype=None, order=’C’)
shape指定形状 一般可以是 2 或者 (2,3) 之类的
fill_value指定填充的值
1 | np.full(shape=(2,3),fill_value=5) |
4、np.eye(N, M=None, k=0, dtype=floa
功能:创建一个方阵(行和列的数量相等)
N 指定矩阵中有多少行和列
对角线为1其他的位置为0(单位矩阵)
5、 np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
功能:把start到stop的这个范围的数,等分成num份儿,填入数组
6、np.logspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
功能:把start到stop的这个范围的数,等分成num份儿,获得的值作为10的指数,求出来的值,填入数组
7、 np.arange([start, ]stop, [step, ]dtype=None)
从start,到end,每隔step去一个值,放入一个数组
8、np.random.randint(low, high=None, size=None, dtype=’l’)
从low到high的范围随机取整数,填充多维数组 size用于指定数组的形状 如 2 (2,3)
9、np.random.randn(d0, d1, …, dn)
传入几个参数,就创建几维数组
产生以0为中心 方差为1 的 标准正太分布 的随机数 填充数组
如 np.random.randn(2,3,3) 产生一个三维数组 数组中有两个数组 两个数组中分别有三个数组 三个数组中每个都有三个元素
10、np.random.normal(loc=0.0, scale=1.0, size=None)
np.random.randn是标准正态分布(以0为中心,方差是1) normal可以指定中心和方差
loc 正态分别的中心
scale 正态分布的变化范围
size 数组的形状 如 2 (2,3)
11、np.random.random(size=None)
size指定三维数组的形状 如 2 (2,3)
函数随机生成0到1的随机数(左闭右开)填充数组
ndarray的属性
4个必记参数:
ndim:维度
shape:形状(各维度的长度)
size:总长度
dtype:元素类型
Matplotlib
Matplotlib 是 Python 的绘图库。 它可与 NumPy 一起使用,提供了一种有效的 MatLab 开源替代方案。 它也可以和图形工具包一起使用,如 PyQt 和 wxPython。
1.引入matplotlib.pyplot
1 | import matplotlib.pyplot as plt |
2.读取图片 pyplot.imread(要读取的文件路的径字)
1 | jin = plt.imread("./jin.png") |
3.查看引入的图片的属性(其实图片就是一个三维数组)
1 | jin # 其实图片就是一个三维数组 |
4.根据传入的数据去绘制图片 pyplot.imshow(传入多维数组数据)
ndarray的基本操作
索引
ndarray对象的内容可以通过索引或切片来访问和修改,就像 Python 的内置容器对象一样。
如前所述,ndarray对象中的元素遵循基于零的索引。 有三种可用的索引方法类型: 字段访问,基本切片和高级索引。
基本切片是 Python 中基本切片概念到 n 维的扩展。 通过将start,stop和step参数提供给内置的slice函数来构造一个 Python slice对象。 此slice对象被传递给数组来提取数组的一部分。
基本索引:一维与列表完全一致 多维时同理
切片
一维与列表切片完全一致 多维时同理
1 | nd = np.random.randint(0,10,size=(5,4)) |
变形
使用reshape函数,注意参数是一个tuple!
连结
- np.concatenate() 连结需要注意的点:
- 连结的参数是列表:一定要加小括号
- 维度必须相同
- 形状相符
- 连结的方向默认是shape这个tuple的第一个值所代表的维度方向
- 可通过axis参数改变连结的方向
切分
与级联类似,三个函数完成切分工作:
- np.split
参数 1.要切分的数组 ;2.要分成几份; 3切分时候的轴(axis默认是0)
- np.vsplit
vertical ,对垂直方向的元素进行切割(切割的时候是水平去切的)
- np.hsplit
horizon ,对水平方向上的元素进行切割(切的时候垂直切)
副本
所有赋值运算不会为ndarray的任何元素创建副本。对赋值后的对象的操作也对原来的对象生效。
可使用copy()函数创建副本
1 | ndarr2 = ndarr.copy() #多维数组调用自身的copy()方法 就会返回一个一模一样 但是完全独立的数组 |
ndarray的聚合操作
求和np.sum
最大最小值:np.max/ np.min
其他聚合操作
1 | Function Name NaN-safe Version Description |
操作文件
使用pandas打开文件president_heights.csv 获取文件中的数据
1 | import pandas as pd |
ndarray的矩阵操作
基本矩阵操作
1) 算术运算符:
- 加减乘除
1 | ndarr = np.random.randint(0,10,size=(4,5)) |
2) 矩阵积numpy.dot()
此函数返回两个数组的点积。 对于二维向量,其等效于矩阵乘法。 对于一维数组,它是向量的内积。 对于 N 维数组,它是a的最后一个轴上的和与b的倒数第二个轴的乘积。
1 | import numpy as np |
输出如下:
1 | [[37 40] |
广播机制
广播是指 NumPy 在算术运算期间处理不同形状的数组的能力。 对数组的算术运算通常在相应的元素上进行。 如果两个阵列具有完全相同的形状,则这些操作被无缝执行。
如果两个数组的维数不相同,则元素到元素的操作是不可能的。 然而,在 NumPy 中仍然可以对形状不相似的数组进行操作,因为它拥有广播功能。 较小的数组会广播到较大数组的大小,以便使它们的形状可兼容。
如果满足以下规则,可以进行广播:
ndim较小的数组会在前面追加一个长度为 1 的维度。- 输出数组的每个维度的大小是输入数组该维度大小的最大值。
- 如果输入在每个维度中的大小与输出大小匹配,或其值正好为 1,则在计算中可它。
- 如果输入的某个维度大小为 1,则该维度中的第一个数据元素将用于该维度的所有计算。
如果上述规则产生有效结果,并且满足以下条件之一,那么数组被称为可广播的。
- 数组拥有相同形状。
- 数组拥有相同的维数,每个维度拥有相同长度,或者长度为 1。
- 数组拥有极少的维度,可以在其前面追加长度为 1 的维度,使上述条件成立。
【重要】ndarray广播机制规则
- 缺失元素用已有值填充
1 | a = np.arange(3).reshape((3, 1)) |
ndarray的排序
快速排序
numpy.sort()与ndarray.sort()都可以,但有区别:
- numpy.sort()不改变输入
- ndarray.sort()本地处理,不占用空间,但改变输入
部分排序
np.partition(a,k)
有的时候我们不是对全部数据感兴趣,我们可能只对最小或最大的一部分感兴趣。
- 当k为正时,我们想要得到最小的k个数
- 当k为负时,我们想要得到最大的k个数
1 | ndarr3 = np.random.randint(0,100,size=15) |
字符串函数
以下函数用于对dtype为numpy.string_或numpy.unicode_的数组执行向量化字符串操作。 它们基于 Python 内置库中的标准字符串函数。
| 序号 | 函数及描述 |
|---|---|
| 1. | add() 返回两个str或Unicode数组的逐个字符串连接 |
| 2. | multiply() 返回按元素多重连接后的字符串 |
| 3. | center() 返回给定字符串的副本,其中元素位于特定字符串的中央 |
| 4. | capitalize() 返回给定字符串的副本,其中只有第一个字符串大写 |
| 5. | title() 返回字符串或 Unicode 的按元素标题转换版本 |
| 6. | lower() 返回一个数组,其元素转换为小写 |
| 7. | upper() 返回一个数组,其元素转换为大写 |
| 8. | split() 返回字符串中的单词列表,并使用分隔符来分割 |
| 9. | splitlines() 返回元素中的行列表,以换行符分割 |
| 10. | strip() 返回数组副本,其中元素移除了开头或者结尾处的特定字符 |
| 11. | join() 返回一个字符串,它是序列中字符串的连接 |
| 12. | replace() 返回字符串的副本,其中所有子字符串的出现位置都被新字符串取代 |
| 13. | decode() 按元素调用str.decode |
| 14. | encode() 按元素调用str.encode |
这些函数在字符数组类(numpy.char)中定义。 较旧的 Numarray 包包含chararray类。 numpy.char类中的上述函数在执行向量化字符串操作时非常有用。
numpy.char.add()
函数执行按元素的字符串连接。
1 | import numpy as np |
输出如下:
1 | 连接两个字符串: |
numpy.char.multiply()
这个函数执行多重连接。
1 | import numpy as np |
输出如下:
1 | Hello Hello Hello |
numpy.char.center()
此函数返回所需宽度的数组,以便输入字符串位于中心,并使用fillchar在左侧和右侧进行填充。
1 | import numpy as np |
输出如下:
1 | *******hello******** |
numpy.char.capitalize()
函数返回字符串的副本,其中第一个字母大写
1 | import numpy as np |
输出如下:
1 | Hello world |
numpy.char.title()
返回输入字符串的按元素标题转换版本,其中每个单词的首字母都大写。
1 | import numpy as np |
输出如下:
1 | Hello How Are You? |
numpy.char.lower()
函数返回一个数组,其元素转换为小写。它对每个元素调用str.lower。
1 | import numpy as np |
输出如下:
1 | ['hello' 'world'] |
numpy.char.upper()
函数返回一个数组,其元素转换为大写。它对每个元素调用str.upper。
1 | import numpy as np |
输出如下:
1 | HELLO |
numpy.char.split()
此函数返回输入字符串中的单词列表。 默认情况下,空格用作分隔符。 否则,指定的分隔符字符用于分割字符串。
1 | import numpy as np |
输出如下:
1 | ['hello', 'how', 'are', 'you?'] |
numpy.char.splitlines()
函数返回数组中元素的单词列表,以换行符分割。
1 | import numpy as np |
输出如下:
1 | ['hello', 'how are you?'] |
'\n','\r','\r\n'都会用作换行符。
numpy.char.strip()
函数返回数组的副本,其中元素移除了开头或结尾处的特定字符。
1 | import numpy as np |
输出如下:
1 | shok aror |
numpy.char.join()
这个函数返回一个字符串,其中单个字符由特定的分隔符连接。
1 | import numpy as np |
输出如下:
1 | d:m:y |
numpy.char.replace()
这个函数返回字符串副本,其中所有字符序列的出现位置都被另一个给定的字符序列取代。
1 | import numpy as np |
输出如下:
1 | He was a good boy |
numpy.char.decode()
这个函数在给定的字符串中使用特定编码调用str.decode()。
1 | import numpy as np |
输出如下:
1 | \x88\x85\x93\x93\x96 |
numpy.char.encode()
此函数对数组中的每个元素调用str.encode函数。 默认编码是utf_8,可以使用标准 Python 库中的编解码器。
1 | import numpy as np |
输出如下:
1 | \x88\x85\x93\x93\x96 |
Pandas
官方文档
数据分析三剑客 numpy pandas matplotlib
Pandas介绍
Pandas是一个开放源码的Python库,它使用强大的数据结构提供高性能的数据操作和分析工具。它的名字:Pandas是从Panel Data - 多维数据的计量经济学(an Econometrics from Multidimensional data)。
2008年,为满足需要高性能,灵活的数据分析工具,开发商Wes McKinney开始开发Pandas。
在Pandas之前,Python主要用于数据迁移和准备。它对数据分析的贡献更小。 Pandas解决了这个问题。 使用Pandas可以完成数据处理和分析的五个典型步骤,而不管数据的来源 - 加载,准备,操作,模型和分析。
Python Pandas用于广泛的领域,包括金融,经济,统计,分析等学术和商业领域。
Pandas的主要特点
- 快速高效的DataFrame对象,具有默认和自定义的索引。
- 将数据从不同文件格式加载到内存中的数据对象的工具。
- 丢失数据的数据对齐和综合处理。
- 重组和摆动日期集。
- 基于标签的切片,索引和大数据集的子集。
- 可以删除或插入来自数据结构的列。
- 按数据分组进行聚合和转换。
- 高性能合并和数据加入。
- 时间序列功能。
数据结构
Pandas处理以下三个数据结构 -
- 系列(
Series) - 数据帧(
DataFrame) - 面板(
Panel)
这些数据结构构建在Numpy数组之上,这意味着它们很快。
维数和描述
考虑这些数据结构的最好方法是,较高维数据结构是其较低维数据结构的容器。 例如,DataFrame是Series的容器,Panel是DataFrame的容器。
| 数据结构 | 维数 | 描述 |
|---|---|---|
| 系列 | 1 | 1D标记均匀数组,大小不变。 |
| 数据帧 | 2 | 一般2D标记,大小可变的表结构与潜在的异质类型的列。 |
| 面板 | 3 | 一般3D标记,大小可变数组。 |
构建和处理两个或更多个维数组是一项繁琐的任务,用户在编写函数时要考虑数据集的方向。 但是使用Pandas数据结构,减少了用户的思考。
例如,使用表格数据(DataFrame),在语义上更有用于考虑索引(行)和列,而不是轴0和轴1。
可变性
所有Pandas数据结构是值可变的(可以更改),除了系列都是大小可变的。系列是大小不变的。
注 -
DataFrame被广泛使用,是最重要的数据结构之一。面板使用少得多。
系列(Series)
系列是具有均匀数据的一维数组结构。例如,以下系列是整数:10,23,56,...的集合。

关键点
- 均匀数据
- 尺寸大小不变
- 数据的值可变
数据帧(DataFrame)
数据帧(DataFrame)是一个具有异构数据的二维数组。
关键点
- 异构数据
- 大小可变
- 数据可变
面板(Panel)
面板是具有异构数据的三维数据结构。在图形表示中很难表示面板。但是一个面板可以说明为DataFrame的容器。
关键点
- 异构数据
- 大小可变
- 数据可变
Series(系列)
Series是一种类似于一维数组的对象,由下面两个部分组成:
- index:相关的数据索引标签
- values:一组数据(ndarray类型)
1. Series的创建
两种创建方式:
(1) 由列表或numpy数组创建
1 | 默认索引为0到N-1的整数型索引 |
(2) 由字典创建
1 | Series({"A":10,"B":20,"C":30}) |
2. Series的索引和切片
可以使用中括号取单个索引(此时返回的是元素类型),或者中括号里一个列表取多个索引(此时返回的仍然是一个Series类型)。分为显示索引和隐式索引:
(1) 显式索引:
1 | - 使用index中的元素作为索引值 |
注意,此时是闭区间
(2) 隐式索引:
1 | - 使用整数作为索引值 |
注意,此时是半开区间
根据索引对Series进行切片
1 | s1 |
3. Series的常用属性和方法
可以把Series看成一个定长的有序字典
可以通过shape,size,index,values等得到series的属性
head(),tail()快速查看Series对象的样式
例:s.head(2)看头两个 s.tail(1)看后一个
当索引没有对应的值时,可能出现缺失数据显示NaN(not a number)的情况
使用pd.isnull(),pd.notnull(),或自带isnull(),notnull()函数检测缺失数据
Series对象本身及其实例都有一个name属性
1 | Series([1,2,3],index=("a","b","c"),name="张三") |
4. Series的运算
(1) 适用于numpy的数组运算也适用于Series
(2) Series之间的运算
- 在运算中自动对齐不同索引的数据
- 如果索引不对应,则补NaN
- 注意:要想保留所有的index,则需要使用.add()函数
1 | s1 |
DataFrame(数据帧)
DataFrame是一个【表格型】的数据结构,可以看做是【由Series组成的字典】(共用同一个索引)。DataFrame由按一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
- 行索引:index
- 列索引:columns
- 值:values(numpy的二维数组)
pandas中的DataFrame可以使用以下构造函数创建 -
1 | pandas.DataFrame( data, index, columns, dtype, copy) |
构造函数的参数如下 -
| 编号 | 参数 | 描述 |
|---|---|---|
| 1 | data |
数据采取各种形式,如:ndarray,series,map,lists,dict,constant和另一个DataFrame。 |
| 2 | index |
对于行标签,要用于结果帧的索引是可选缺省值np.arrange(n),如果没有传递索引值。 |
| 3 | columns |
对于列标签,可选的默认语法是 - np.arange(n)。 这只有在没有索引传递的情况下才是这样。 |
| 4 | dtype |
每列的数据类型。 |
| 5 | copy |
如果默认值为False,则此命令(或任何它)用于复制数据。 |
1. DataFrame的创建
最常用的方法是传递一个字典来创建。DataFrame以字典的键作为每一【列】的名称,以字典的值(一个数组)作为每一列。
此外,DataFrame会自动加上每一行的索引(和Series一样)。
同Series一样,若传入的列与字典的键不匹配,则相应的值为NaN。
1 | import numpy as np |
2. DataFrame的索引
(1) 对 列 进行索引
— 通过类似字典的方式
— 通过属性的方式
可以将DataFrame的列获取为一个Series。返回的Series拥有原DataFrame相同的索引,且name属性也已经设置好了,就是相应的列名。
每一行是一个样本 每一列是描述这个样本的维度
(2) 对 行 进行索引
— 使用.loc[]加index来进行行索引
— 使用.iloc[]加整数来进行行索引
同样返回一个Series,index为原来的columns。
总结:
columns 才能以索引的形式去找 df [“列名”] 、df.列名
index 不能用索引的方式去找 只能用 loc[] 和 iloc[] 去定位内容
(3) 对元素进行索引
— 使用列索引
— 使用行索引( iloc[3,1]相当于两个参数; iloc[[3,3]] 里面的[3,3]看做一个参数)
— 使用values属性(二维numpy数组)
【注意】 直接用中括号 [ ] 时:
- 索引表示的是列索引
- 切片表示的是行切片
3. DataFrame的运算
(1) DataFrame和数值的运算
1 | DataFrame + 1 # 所有内容都加一 |
(2) DataFrame与DataFrame之间的运算
同Series一样:
- 在运算中自动对齐不同索引的数据
- 如果索引不对应,则补NaN
下面是Python 操作符与pandas操作函数的对应表:
| Python Operator | Pandas Method(s) |
|---|---|
+ |
add() |
- |
sub(), subtract() |
* |
mul(), multiply() |
/ |
truediv(), div(), divide() |
// |
floordiv() |
% |
mod() |
** |
pow() |
(3) DataFrame和Series之间的运算
【重要】
使用Python操作符:以行为单位操作(参数必须是行),对所有行都有效。(类似于numpy中二维数组与一维数组的运算,但可能出现NaN)
使用pandas操作函数:
— axis=0:以列为单位操作(参数必须是列),对所有列都有效。
-- axis=1:以行为单位操作(参数必须是行),对所有行都有效。
空数据处理
检查缺失值
isnull()和notnull()函数 ,它们也是Series和DataFrame对象的方法
配合any使用,可以查看每一 行 / 列 是否存在空值 可以控制axis来改变查看方向
1 | df1 = DataFrame(data=np.random.randint(0,20,size=(5,5)),columns=list("abcde")) |
过滤丢失数据
dropna(): 过滤丢失数据
1 | dropna(axis, how) # axis 删除有NaN的行还是列,how 要有NaN就删 还是全都是NaN才删 |
1 | df1.dropna() # 如果有空值 就把整行都干掉 |
填充缺少数据
fillna()函数可以用非空数据“填充”NaN值
— value :指定填充的值
— method :指定找前面还是找后面
— axis :指定是横着找还是竖着找
— limit:限定往前/后找几个
注意:value参数是不能跟method参数共用的
1 | df1.fillna(value=0) # 遇到空值 可以设置成我们制定的值 |
多层索引
多层行索引
创建MultiIndex(分层索引)对象
该MultiIndex对象是标准Index对象的分层模拟 ,通常将轴标签存储在pandas对象中
数组列表(使用 MultiIndex.from_arrays)
1 | index = pd.MultiIndex.from_arrays([["期中","期中","期中","期末","期末","期末"],["语文","英语","数学","语文","英语","数学"]]) |
元组数组(使用MultiIndex.from_tuples)
1 | index = pd.MultiIndex.from_tuples([("期中","语文"),("期中","数学"),("期中","英语"),("期末","语文"),("期末","数学"),("期末","英语")]) |
交叉迭代集(使用 MultiIndex.from_product),最简单,推荐使用
1 | index = pd.MultiIndex.from_product([["期中","期末"],["语文","数学","英语"]]) |
多层列索引
除了行索引index,列索引columns也能用同样的方法创建多层索引
1 | data = np.random.randint(0,150,size=(2,4)) |
索引与切片操作
Series的操作
【重要】对于Series来说,直接中括号 [ ] 与使用 .loc() 完全一样,推荐使用 .loc 中括号索引和切片。
DataFrame的操作
(1) 可以直接使用列名称来进行列索引
1 | df1["期中"]["语文"] |
(2) 使用行索引需要用 loc() 等函数
1 | df1.loc["张三"] |
形状变换
stack()
columns -> index 列标题变行标题(数据也会跟着标题走)
level 的值默认为-1(最内层);取值从外往里 从0递增
1 | df.stack(level=0) # level 索引的级别 默认是-1 -1就是最里面的 level的值 从外到内 0 1 2 3 |
unstack()
index -> columns 行标题变列标题(数据也会跟着标题走)
聚合操作
| 功能 | 描述 |
|---|---|
count() |
Number of non-null observations |
sum() |
对 values 求和 |
mean() |
values 的平均值 |
min() |
求 values 最小值 |
max() |
求 values 最大值 |
1 | # 如果想对 行进行聚合操作 可以调整 axis |
合并、连接
pandas的拼接分为两种:
- 级联:pandas.concat, pandas.append (没有重复数据)
- 合并:pandas.merge, pandas.join (有重复数据)
pandas.concat()级联
简单级联
pandas使用pandas.concat函数,与numpy.concatenate函数类似
1 | pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, |
参数:
objs 传入列表或者元素 里面是要拼接的DataFrame
axis 拼接的时候是沿着什么方向 默认值是0 纵向 如果是1就是横向
join 指定了拼接的方式 默认是outer
— outer 外联 所有的列都会拼进来
— inner 内联 只有那些两个DataFrame都有的列才会拼进来
join_axes 直接指定那些列要放进来
ignore_index=False 忽略原有索引创建新的索引 (如果索引有重复可以通过忽略原索引来重置)
keys 可以把不同的DataFrame分成多组 也可以用来解决index重复的问题
1 | df3 = pd.concat((df1,df2)) #默认 axis是0 是纵向拼接 |
不匹配级联
不匹配指的是级联的维度的索引不一致。例如纵向级联时列索引不一致,横向级联时行索引不一致
有3种连接方式:
- 外连接:补NaN(默认模式) join=’outer’
- 内连接:只连接匹配的项 join=’inner’
- 连接指定轴 join_axes
pandas.append()函数添加
由于在后面级联的使用非常普遍,因此有一个函数pandas.append()专门用于在后面添加
1 | df6.append(df7) # 只能是把行 纵向地 从后 往前 拼接 |
pandas.merge()合并
merge与concat的区别在于,merge需要依据某一共同的行或列来进行合并
使用pd.merge()合并时,会自动根据两者相同column名称的那一列,作为key来进行合并。
注意每一列元素的顺序不要求一致
1 | pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, |
在这里,有以下几个参数可以使用 -
left - 一个DataFrame对象。
right - 另一个DataFrame对象。
on - 列(名称)连接,必须在左和右DataFrame对象中存在(找到)。
left_on - 左侧DataFrame中的列用作键,可以是列名或长度等于DataFrame长度的数组。
right_on - 来自右的DataFrame的列作为键,可以是列名或长度等于DataFrame长度的数组。
left_index - 如果为
True,则使用左侧DataFrame中的索引(行标签)作为其连接键。 在具有MultiIndex(分层)的DataFrame的情况下,级别的数量必须与来自右DataFrame的连接键的数量相匹配。right_index - 与右DataFrame的left_index具有相同的用法。
how - 它是left, right, outer以及inner之中的一个,默认为内inner。
— inner 是取交集 两个都有的项目才出现
— outer 是取并集 任何一个表格里出现的项目都会出现
— left 左边的表格有多少项目 这里就有多少项目
— right 右边的表格有多少项目 这里就有多少项目
sort - 按照字典顺序通过连接键对结果DataFrame进行排序。默认为
True,设置为False时,在很多情况下大大提高性能。
key的规范化
— 使用on=显式指定哪一列为key,当有多个key相同时使用
— 使用left_on和right_on指定左右两边的列作为key,当左右两边的key都不想等时使用
内合并与外合并
— 内合并:只保留两者都有的key(默认模式)
— 外合并 how=’outer’:补NaN
— 左合并、右合并:how=’left’,how=’right’,
列冲突的解决
— 当列冲突时,即有多个列名称相同时,需要使用on=来指定哪一个列作为key,配合suffixes指定冲突列名
— 可以使用suffixes=自己指定后缀
IO
Pandas I/O API是一套像pd.read_csv()一样返回Pandas对象的顶级读取器函数。
读取文本文件(或平面文件)的两个主要功能是read_csv()和read_table()。它们都使用相同的解析代码来智能地将表格数据转换为DataFrame对象
1 | pandas.read_csv(filepath_or_buffer, sep=',', delimiter=None, header='infer', |
read.csv
read.csv从csv文件中读取数据并创建一个DataFrame对象。
1 | import pandas as pd |
执行上面示例代码,得到以下结果 -
1 | S.No Name Age City Salary |
自定义索引
可以指定csv文件中的一列来使用index_col定制索引。
1 | import pandas as pd |
执行上面示例代码,得到以下结果 -
1 | Name Age City Salary |
转换器dtype的列可以作为字典传递。
1 | import pandas as pd |
执行上面示例代码,得到以下结果 -
1 | S.No int64 |
默认情况下,Salary列的dtype是int,但结果显示为float,因为我们明确地转换了类型。
因此,数据看起来像浮点数 -
1 | S.No Name Age City Salary |
header_names
使用names参数指定标题的名称。
1 | import pandas as pd |
执行上面示例代码,得到以下结果 -
1 | a b c d e |
观察可以看到,标题名称附加了自定义名称,但文件中的标题还没有被消除。 现在,使用header参数来删除它。
如果标题不是第一行,则将行号传递给标题。这将跳过前面的行。
1 | import pandas as pd |
执行上面示例代码,得到以下结果 -
1 | a b c d e |
skiprows
skiprows跳过指定的行数。参考以下示例代码 -
1 | import pandas as pd |
执行上面示例代码,得到以下结果 -
1 | 2 Lee 32 HongKong 3000 |
去重
使用duplicated()函数检测重复的行,返回元素为布尔类型的Series对象,每个元素对应一行,如果该行不是第一次出现,则元素为True(是重复的)
- 使用drop_duplicates()函数删除重复的行
- 使用duplicate()函数查看重复的行
1 | python c++ java |
替换
映射
映射的含义:创建一个映射关系列表,把values元素和一个特定的标签或者字符串绑定
包含三种操作:
- replace()函数:替换元素
- 最重要:map()函数:新建一列
- rename()函数:替换索引
replace()函数:替换元素
使用replace()函数,对values进行替换操作
Series替换操作
单值替换
- 普通替换
- 字典替换(推荐)
多值替换
- 列表替换
- 字典替换(推荐)
1 | # 单值替换 普通替换 |
Series参数说明:
- method:对指定的值使用相邻的值填充
- limit:设定填充次数
1 | # 如果指定value不好 还可以找值来填充 |
DataFrame替换操作
单值替换
- 普通替换
- 按列指定单值替换{列标签:目标值}
多值替换
- 列表替换
- 单字典替换(推荐)
1 | # 普通的单值替换 |
注意:DataFrame中,无法使用method和limit参数
map()函数:新建一列
- map(字典) 字典的键要足以匹配所有的数据,否则出现NaN
- map()可以映射新一列数据
- map()中可以使用lambd表达式
- map()中可以使用方法,可以是自定义的方法
注意 map()中不能使用sum之类的函数,for循环
1 | 姓名 语文 数学 python php |
1 | # 映射字典 |
1 | # map函数不是DataFrame的方法,而是Sereis对象的方法 |
1 | score["所在城市"] = score["姓名"].map(map_dic) # 可以传入字典 |
1 | # 还可以传入 拉姆达表达式 如 lambda x:x+10 |
rename()函数:替换索引
对DataFrame的索引名进行更改 , 仍然是新建一个字典
使用rename()函数替换行索引
- index 替换行索引
- columns 替换列索引
- level 指定多维索引的维度
1 | score.rename(map_dic) # 默认是替换 行的名称 |
异常检测和过滤
使用 df.describe() 函数查看每一列的描述性统计量
1 | data = np.random.randn(1000,5) |
使用std()函数可以求得DataFrame对象每一列的标准差
根据每一列或行的标准差,对DataFrame元素进行过滤。
借助any()或all()函数, 测试是否有True,有一个或以上返回True,反之返回False
对每一列应用筛选条件,去除标准差太大的数据
1 | # 寻找异常数据 太大的 或者 太小的 |
删除特定索引df.drop(labels,inplace = True)
排序
Pandas有两种排序方式,它们分别是 -
- 按标签
- 按实际值
按标签排序
使用sort_index()方法,通过传递axis参数和排序顺序,可以对DataFrame进行排序。 默认情况下,按照升序对行标签进行排序。
按列排列
通过传递axis参数值为0或1,可以对列标签进行排序。 默认情况下,axis = 0,逐行排列。来看看下面的例子来理解这个概念。
按值排序
像索引排序一样,sort_values()是按值排序的方法。它接受一个by参数,它将使用要与其排序值的DataFrame的列名称。
排序算法
sort_values()提供了从mergeesort,heapsort和quicksort中选择算法的一个配置。Mergesort是唯一稳定的算法。
使用.take()函数排序
1 | - take()函数接受一个索引列表,用数字表示 |
可以借助np.random.permutation()函数随机排序使用.take()函数排序
1 | - take()函数接受一个索引列表,用数字表示 |
可以借助np.random.permutation()函数随机排序
1 | data = np.random.randint(0,100,size=(5,5)) |
随机抽样
当DataFrame规模足够大时,直接使用np.random.randint()函数,就配合take()函数实现随机抽样
1 | np.random.randint(0,5,size=2) |
分类
数据分类处理:
- 分组:先把数据分为几组
- 用函数处理:为不同组的数据应用不同的函数以转换数据
- 合并:把不同组得到的结果合并起来
数据分类处理的核心:
— groupby()函数
— groups属性查看分组情况
1 | df = DataFrame({'item':['苹果','香蕉','橘子','香蕉','橘子','苹果','苹果'], |
根据item分组,通过groups属性查看结果
1 | df.groupby("item").groups |
获取weight的总和
1 | df.groupby("item")["weight"].sum() #各类水果的总重量 |
Matplotlib
matplotlib在Python中应用最多的2D图像的绘图工具包,使用matplotlib能够非常简单的可视化数据。在matplotlib中使用最多的模块就是pyplot。pyplot非常接近Matlab的绘图实现,而且大多数的命令及其类似Matlab.当然,与Matlab类似,需要很多的数学运算,因此numpy这个组件同样是必不可少的。所以很多人说python+matplotlib+numpy就是MATLAB。
一、Matplotlib基础知识
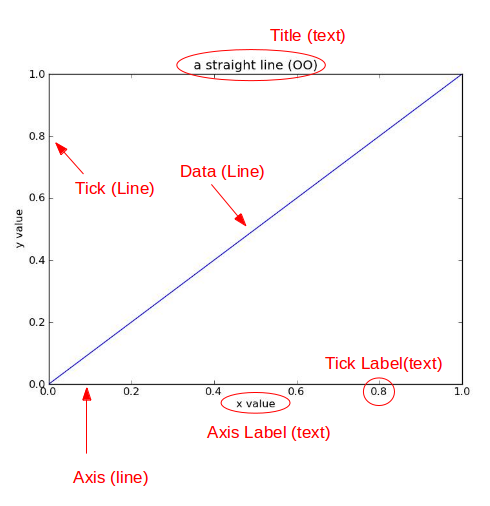
Matplotlib中的基本图表包括的元素
- x轴和y轴—axis , 水平和垂直的轴线
- 轴标签—axisLabel , 水平和垂直的轴标签
- x轴和y轴刻度—tick , 刻度标示坐标轴的分隔,包括最小刻度和最大刻度
- x轴和y轴刻度标签—tick label , 表示特定坐标轴的值
- 绘图区域(坐标系)—axes , 实际绘图的区域
- 画布—figure , 呈现所有的坐标系
只含单一曲线的图
1、可以使用多个plot函数(推荐),在一个图中绘制多个曲线
2、也可以在一个plot函数中传入多对X,Y值,在一个图中绘制多个曲线
设置子画布
axes = plt.subplot()
网格线
绘制正弦余弦
使用plt.grid方法可以开启网格线,使用plt面向对象的方法,创建多个子图显示不同网格线

- lw代表linewidth,线的粗细
- alpha表示线的明暗程度
- color代表颜色
- axis显示轴向
坐标轴界限
plt.axis([xmin,xmax,ymin,ymax])
plt.axis(‘xxx’) ‘tight’、’off’、’equal’……
设置坐标轴类型
关闭坐标轴
xlim方法和ylim方法
除了plt.axis方法,还可以通过xlim,ylim方法设置坐标轴范围
坐标轴标签
xlabel方法和ylabel方法
plt.ylabel(‘y = x^2 + 5’,rotation = 60)旋转
- color 标签颜色
- fontsize 字体大小
- rotation 旋转角度
标题
plt.title()方法
- loc {left,center,right}
- color 标签颜色
- fontsize 字体大小
- rotation 旋转角度
图例
legend方法
两种传参方法:
- 分别在plot函数中增加label参数,再调用legend()方法显示
- 直接在legend方法中传入字符串列表
loc参数
- loc参数用于设置图例标签的位置,一般在legend函数内
- matplotlib已经预定义好几种数字表示的位置
| 字符串 | 数值 | 字符串 | 数值 |
|---|---|---|---|
| best | 0 | center left | 6 |
| upper right | 1 | center right | 7 |
| upper left | 2 | lower center | 8 |
| lower left | 3 | upper center | 9 |
| lower right | 4 | center | 10 |
| right | 5 |
loc参数可以是2元素的元组,表示图例左下角的坐标
- [0,0] 左下
- [0,1] 左上
- [1,0] 右下
- [1,1] 右上
图例也可以超过图的界限loc = (-0.1,0.9)
ncol参数
ncol控制图例中有几列,在legend中设置ncol,需要设置loc
linestyle、color、marker
修改线条样式
- linestyle(ls) 设置线的风格
- linewidth(lw) 设置线宽
- alpha 透明度
- color 颜色
- marker 点形
- markersize 点大小
- markeredagecolor 点的边界颜色
- markeredagewidth 点的边界宽度
- markerfacecolor 点的主体颜色
保存图片
使用figure对象的savefig的函数
- filename
含有文件路径的字符串或Python的文件型对象。图像格式由文件扩展名推断得出,例如,.pdf推断出PDF,.png推断出PNG (“png”、“pdf”、“svg”、“ps”、“eps”……) - dpi
图像分辨率(每英寸点数),默认为100 - facecolor
图像的背景色,默认为“w”(白色)
二、设置plot的风格和样式
plot语句中支持除X,Y以外的参数,以字符串形式存在,来控制颜色、线型、点型等要素,语法形式为:
plt.plot(X, Y, ‘format’, …)
点和线的样式
颜色
参数color或c
颜色值的方式
别名
- color=’r’
合法的HTML颜色名
- color = ‘red’
| 颜色 | 别名 | HTML颜色名 | 颜色 | 别名 | HTML颜色名 |
|---|---|---|---|---|---|
| 蓝色 | b | blue | 绿色 | g | green |
| 红色 | r | red | 黄色 | y | yellow |
| 青色 | c | cyan | 黑色 | k | black |
| 洋红色 | m | magenta | 白色 | w | white |
HTML十六进制字符串
- color = ‘#eeefff’
归一化到[0, 1]的RGB元组
- color = (0.3, 0.3, 0.4)
jpg png 区别
透明度
alpha参数
背景色
设置背景色,通过plt.subplot()方法传入facecolor参数,来设置坐标系的背景色
线型
参数linestyle或ls
| 线条风格 | 描述 | 线条风格 | 描述 |
|---|---|---|---|
| ‘-‘ | 实线 | ‘:’ | 虚线 |
| ‘—‘ | 破折线 | ‘steps’ | 阶梯线 |
| ‘-.’ | 点划线 | ‘None’ / ‘,’ | 什么都不画 |
不同宽度的破折线
dashes参数 eg.dashes = [20,50,5,2,10,5]
设置破折号序列各段的宽度
点型
- marker 设置点形
- markersize 设置点形大小
| 标记 | 描述 | 标记 | 描述 |
|---|---|---|---|
| ‘1’ | 一角朝下的三脚架 | ‘3’ | 一角朝左的三脚架 |
| ‘2’ | 一角朝上的三脚架 | ‘4’ | 一角朝右的三脚架 |
| 标记 | 描述 | 标记 | 描述 |
|---|---|---|---|
| ‘s’ | 正方形 | ‘p’ | 五边形 |
| ‘h’ | 六边形1 | ‘H’ | 六边形2 |
| ‘8’ | 八边形 |
| 标记 | 描述 | 标记 | 描述 |
|---|---|---|---|
| ‘.’ | 点 | ‘x’ | X |
| ‘*’ | 星号 | ‘+’ | 加号 |
| ‘,’ | 像素 |
| 标记 | 描述 | 标记 | 描述 |
|---|---|---|---|
| ‘o’ | 圆圈 | ‘D’ | 菱形 |
| ‘d’ | 小菱形 | ‘’,’None’,’ ‘,None | 无 |
| 标记 | 描述 | 标记 | 描述 | |
|---|---|---|---|---|
| ‘_’ | 水平线 | ‘\ | ‘ | 竖线 |
| 标记 | 描述 | 标记 | 描述 |
|---|---|---|---|
| ‘v’ | 一角朝下的三角形 | ‘<’ | 一角朝左的三角形 |
| ‘^’ | 一角朝上的三角形 | ‘>’ | 一角朝右的三角形 |
多参数连用
颜色、点型、线型,可以把几种参数写在一个字符串内进行设置 ‘r-.o’
更多点和线的设置
| 参数 | 描述 | 参数 | 描述 |
|---|---|---|---|
| color或c | 线的颜色 | linestyle或ls | 线型 |
| linewidth或lw | 线宽 | marker | 点型 |
| markeredgecolor | 点边缘的颜色 | markeredgewidth | 点边缘的宽度 |
| markerfacecolor | 点内部的颜色 | markersize | 点的大小 |
多个曲线同一设置
属性名声明,不可以多参数连用
plt.plot(x1, y1, x2, y2, fmt, …)
多个曲线不同设置
多个都进行设置时,多参数连用 plt.plot(x1, y1, fmt1, x2, y2, fmt2, …)
三种设置方式
向方法传入关键字参数
- import matplotlib as mpl
对实例使用一系列的setter方法
- plt.plot()方法返回一个包含所有线的列表,设置每一个线需要获取该线对象
- eg: lines = plt.plot(); line = lines[0]
- line.set_linewith()
- line.set_linestyle()
- line.set_color()
对坐标系使用一系列的setter方法
- axes = plt.subplot()获取坐标系
- set_title()
- set_facecolor()
- set_xticks、set_yticks 设置刻度值
- set_xticklabels、set_yticklabels 设置刻度名称
X、Y轴坐标刻度
plt.xticks()和plt.yticks()方法
- 需指定刻度值和刻度名称 plt.xticks([刻度列表],[名称列表])
- 支持fontsize、rotation、color等参数设置
三、2D图形
直方图
【直方图的参数只有一个x!!!不像条形图需要传入x,y】
hist() 的参数
- bins
可以是一个bin数量的整数值,也可以是表示bin的一个序列。默认值为10 - normed
如果值为True,直方图的值将进行归一化处理,形成概率密度,默认值为False - color
指定直方图的颜色。可以是单一颜色值或颜色的序列。如果指定了多个数据集合,颜色序列将会设置为相同的顺序。如果未指定,将会使用一个默认的线条颜色 - orientation
通过设置orientation为horizontal创建水平直方图。默认值为vertical
1 | data = np.random.randint(0,10,size=100) |
条形图
【条形图有两个参数x,y】
- width 纵向设置条形宽度
- height 横向设置条形高度
bar()横向条形图 、 barh()纵向条形图
1 | # 横向条形图 |
饼图
【饼图也只有一个参数x!】
pie()
饼图适合展示各部分占总体的比例,条形图适合比较各部分的大小
普通各部分占满饼图
1 | import numpy as np |
1 | plt.pie([0.3,0.2,0.5]) |
普通未占满饼图
1 | plt.pie([0.3,0.1,0.5]) |
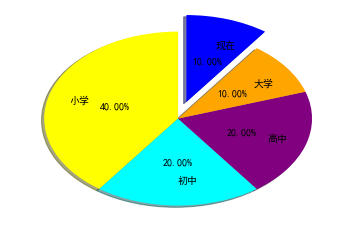
饼图阴影、分裂等属性设置
- labels参数设置每一块的标签;
- labeldistance参数设置标签距离圆心的距离(比例值,只能设置一个浮点小数)
- autopct参数设置比例值的显示格式(%1.1f%%);
- pctdistance参数设置比例值文字距离圆心的距离
- explode参数设置每一块顶点距圆形的长度(比例值,列表);
- colors参数设置每一块的颜色(列表);
- shadow参数为布尔值,设置是否绘制阴影
- startangle参数设置饼图起始角度
1 | plt.rcParams['font.sans-serif'] = ['SimHei'] # 步骤一(替换sans-serif字体) |
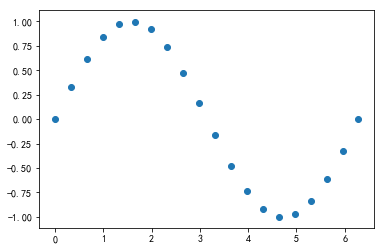
散点图
【散点图需要两个参数x,y,但此时x不是表示x轴的刻度,而是每个点的横坐标!】
scatter()
1 | x = np.linspace(0,2*np.pi,20) |
四、图形内的文字、注释、箭头
控制文字属性的方法:
| pyplot函数 | API方法 | 描述 |
|---|---|---|
| text() | mpl.axes.Axes.text() | 在Axes对象的任意位置添加文字 |
| xlabel() | mpl.axes.Axes.set_xlabel() | 为X轴添加标签 |
| ylabel() | mpl.axes.Axes.set_ylabel() | 为Y轴添加标签 |
| title() | mpl.axes.Axes.set_title() | 为Axes对象添加标题 |
| legend() | mpl.axes.Axes.legend() | 为Axes对象添加图例 |
| figtext() | mpl.figure.Figure.text() | 在Figure对象的任意位置添加文字 |
| suptitle() | mpl.figure.Figure.suptitle() | 为Figure对象添加中心化的标题 |
| annnotate() | mpl.axes.Axes.annotate() | 为Axes对象添加注释(箭头可选) |
所有的方法会返回一个matplotlib.text.Text对象
图形内的文字
text()
注释
annotate()
- xy参数设置箭头指示的位置
- xytext参数设置注释文字的位置
- arrowprops参数以字典的形式设置箭头的样式
- width参数设置箭头长方形部分的宽度
- headlength参数设置箭头尖端的长度,
- headwidth参数设置箭头尖端底部的宽度
- shrink参数设置箭头顶点、尾部与指示点、注释文字的距离(比例值),可以理解为控制箭头的长度
五、3D图
曲面图
导包
- from mpl_toolkits.mplot3d.axes3d import Axes3D
使用mershgrid函数切割x,y轴
- X,Y = np.meshgrid(x, y)
创建3d坐标系
- axes = plt.subplot(projection=’3d’)
绘制3d图形
- p = axes.plot_surface(X,Y,Z,color=’red’,cmap=’summer’,rstride=5,cstride=5)
添加colorbar
- plt.colorbar(p,shrink=0.5)
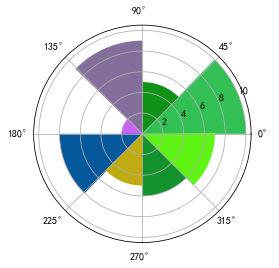
玫瑰图/极坐标条形图
创建极坐标,设置polar属性
- plt.axes(polar = True)
绘制极坐标条形图
- index = np.arange(-np.pi,np.pi,2*np.pi/6)
- plt.bar(x=index ,height = [1,2,3,4,5,6] ,width = 2*np.pi/6)
1 | # 先设置子画布为极坐标画布 |