1、网络爬虫和相关工具
1.1 网络爬虫
网络爬虫(web crawler),以前经常称之为网络蜘蛛(spider),是按照一定的规则自动浏览万维网并获取信息的机器人程序(或脚本),曾经被广泛的应用于互联网搜索引擎。使用过互联网和浏览器的人都知道,网页中除了供用户阅读的文字信息之外,还包含一些超链接。网络爬虫系统正是通过网页中的超链接信息不断获得网络上的其它页面。正因如此,网络数据采集的过程就像一个爬虫或者蜘蛛在网络上漫游,所以才被形象的称为网络爬虫或者网络蜘蛛。
爬虫的应用领域
在理想的状态下,所有ICP(Internet Content Provider)都应该为自己的网站提供API接口来共享它们允许其他程序获取的数据,在这种情况下爬虫就不是必需品,国内比较有名的电商平台(如淘宝、京东等)、社交平台(如腾讯微博等)等网站都提供了自己的Open API,但是这类Open API通常会对可以抓取的数据以及抓取数据的频率进行限制。对于大多数的公司而言,及时的获取行业相关数据是企业生存的重要环节之一,然而大部分企业在行业数据方面的匮乏是其与生俱来的短板,合理的利用爬虫来获取数据并从中提取出有商业价值的信息是至关重要的。当然爬虫还有很多重要的应用领域,下面列举了其中的一部分:
- 搜索引擎
- 新闻聚合
- 社交应用
- 舆情监控
- 行业数据
1.2合法性和背景调研
爬虫合法性探讨
- 网络爬虫领域目前还属于拓荒阶段,虽然互联网世界已经通过自己的游戏规则建立起一定的道德规范(Robots协议,全称是“网络爬虫排除标准”),但法律部分还在建立和完善中,也就是说,现在这个领域暂时还是灰色地带。
- “法不禁止即为许可”,如果爬虫就像浏览器一样获取的是前端显示的数据(网页上的公开信息)而不是网站后台的私密敏感信息,就不太担心法律法规的约束,因为目前大数据产业链的发展速度远远超过了法律的完善程度。
- 在爬取网站的时候,需要限制自己的爬虫遵守Robots协议,同时控制网络爬虫程序的抓取数据的速度;在使用数据的时候,必须要尊重网站的知识产权(从Web 2.0时代开始,虽然Web上的数据很多都是由用户提供的,但是网站平台是投入了运营成本的,当用户在注册和发布内容时,平台通常就已经获得了对数据的所有权、使用权和分发权)。如果违反了这些规定,在打官司的时候败诉几率相当高。
Robots.txt文件
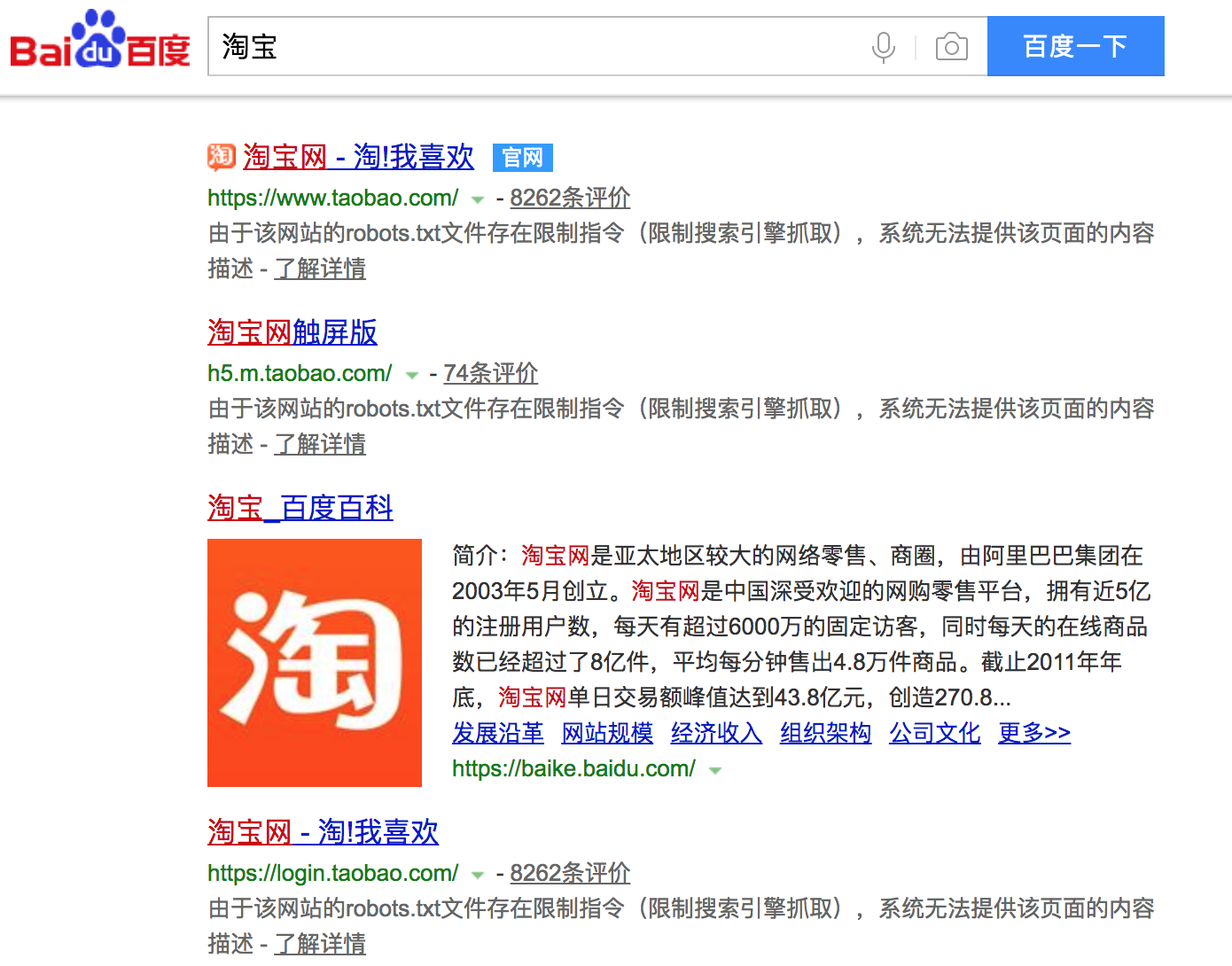
大多数网站都会定义robots.txt文件,下面以淘宝的robots.txt文件为例,看看该网站对爬虫有哪些限制。
1 | User-agent: Baiduspider |
注意上面robots.txt第一段的最后一行,通过设置“Disallow: /”禁止百度爬虫访问除了“Allow”规定页面外的其他所有页面。因此当你在百度搜索“淘宝”的时候,搜索结果下方会出现:“由于该网站的robots.txt文件存在限制指令(限制搜索引擎抓取),系统无法提供该页面的内容描述”。百度作为一个搜索引擎,至少在表面上遵守了淘宝网的robots.txt协议,所以用户不能从百度上搜索到淘宝内部的产品信息。
1.3 相关工具介绍
HTTP协议
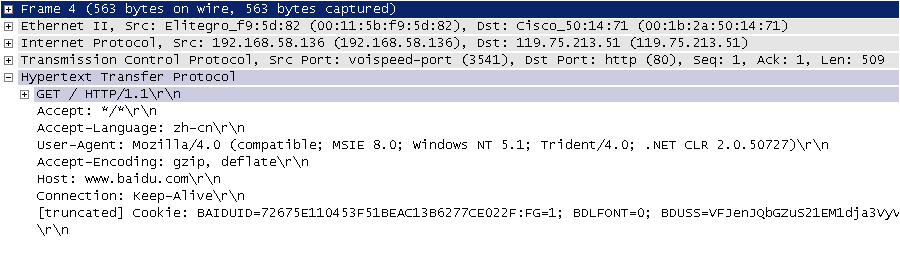
在开始讲解爬虫之前,我们稍微对HTTP(超文本传输协议)做一些回顾,因为我们在网页上看到的内容通常是浏览器执行HTML语言得到的结果,而HTTP就是传输HTML数据的协议。HTTP和其他很多应用级协议一样是构建在TCP(传输控制协议)之上的,它利用了TCP提供的可靠的传输服务实现了Web应用中的数据交换。按照维基百科上的介绍,设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法,也就是说这个协议是浏览器和Web服务器之间传输的数据的载体。关于这个协议的详细信息以及目前的发展状况,大家可以阅读阮一峰老师的《HTTP 协议入门》、《互联网协议入门》系列以及《图解HTTPS协议》进行了解,下图是我在四川省网络通信技术重点实验室工作期间用开源协议分析工具Ethereal(抓包工具WireShark的前身)截取的访问百度首页时的HTTP请求和响应的报文(协议数据),由于Ethereal截取的是经过网络适配器的数据,因此可以清晰的看到从物理链路层到应用层的协议数据。
HTTP请求(请求行+请求头+空行+[消息体]):
HTTP响应(响应行+响应头+空行+消息体):
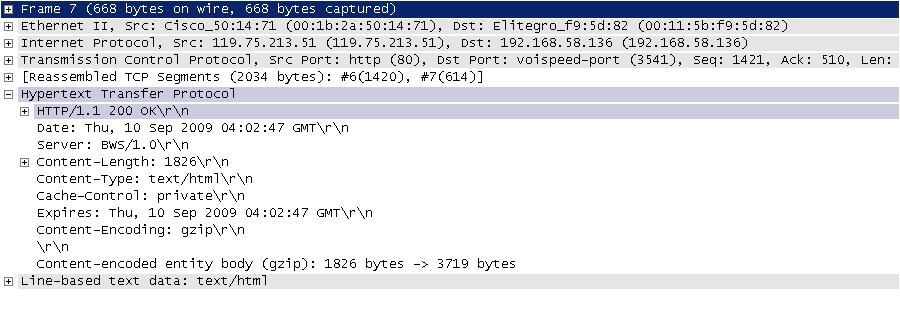
说明:但愿这两张如同泛黄的照片般的截图帮助你大概的了解到HTTP是一个怎样的协议。
相关工具
Chrome Developer Tools:谷歌浏览器内置的开发者工具。
POSTMAN:功能强大的网页调试与RESTful请求工具。
HTTPie:命令行HTTP客户端。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17$ http --header http://www.scu.edu.cn
HTTP/1.1 200 OK
Accept-Ranges: bytes
Cache-Control: private, max-age=600
Connection: Keep-Alive
Content-Encoding: gzip
Content-Language: zh-CN
Content-Length: 14403
Content-Type: text/html
Date: Sun, 27 May 2018 15:38:25 GMT
ETag: "e6ec-56d3032d70a32-gzip"
Expires: Sun, 27 May 2018 15:48:25 GMT
Keep-Alive: timeout=5, max=100
Last-Modified: Sun, 27 May 2018 13:44:22 GMT
Server: VWebServer
Vary: User-Agent,Accept-Encoding
X-Frame-Options: SAMEORIGINBuiltWith:识别网站所用技术的工具。
1
2
3
4
5
6
7
8
9>>>
>>> import builtwith
>>> builtwith.parse('http://www.bootcss.com/')
{'web-servers': ['Nginx'], 'font-scripts': ['Font Awesome'], 'javascript-frameworks': ['Lo-dash', 'Underscore.js', 'Vue.js', 'Zepto', 'jQuery'], 'web-frameworks': ['Twitter Bootstrap']}
>>>
>>> import ssl
>>> ssl._create_default_https_context = ssl._create_unverified_context
>>> builtwith.parse('https://www.jianshu.com/')
{'web-servers': ['Tengine'], 'web-frameworks': ['Twitter Bootstrap', 'Ruby on Rails'], 'programming-languages': ['Ruby']}python-whois:查询网站所有者的工具。
1
2
3
4>>>
>>> import whois
>>> whois.whois('baidu.com')
{'domain_name': ['BAIDU.COM', 'baidu.com'], 'registrar': 'MarkMonitor, Inc.', 'whois_server': 'whois.markmonitor.com', 'referral_url': None, 'updated_date': [datetime.datetime(2017, 7, 28, 2, 36, 28), datetime.datetime(2017, 7, 27, 19, 36, 28)], 'creation_date': [datetime.datetime(1999, 10, 11, 11, 5, 17), datetime.datetime(1999, 10, 11, 4, 5, 17)], 'expiration_date': [datetime.datetime(2026, 10, 11, 11, 5, 17), datetime.datetime(2026, 10, 11, 0, 0)], 'name_servers': ['DNS.BAIDU.COM', 'NS2.BAIDU.COM', 'NS3.BAIDU.COM', 'NS4.BAIDU.COM', 'NS7.BAIDU.COM', 'dns.baidu.com', 'ns4.baidu.com', 'ns3.baidu.com', 'ns7.baidu.com', 'ns2.baidu.com'], 'status': ['clientDeleteProhibited https://icann.org/epp#clientDeleteProhibited', 'clientTransferProhibited https://icann.org/epp#clientTransferProhibited', 'clientUpdateProhibited https://icann.org/epp#clientUpdateProhibited', 'serverDeleteProhibited https://icann.org/epp#serverDeleteProhibited', 'serverTransferProhibited https://icann.org/epp#serverTransferProhibited', 'serverUpdateProhibited https://icann.org/epp#serverUpdateProhibited', 'clientUpdateProhibited (https://www.icann.org/epp#clientUpdateProhibited)', 'clientTransferProhibited (https://www.icann.org/epp#clientTransferProhibited)', 'clientDeleteProhibited (https://www.icann.org/epp#clientDeleteProhibited)', 'serverUpdateProhibited (https://www.icann.org/epp#serverUpdateProhibited)', 'serverTransferProhibited (https://www.icann.org/epp#serverTransferProhibited)', 'serverDeleteProhibited (https://www.icann.org/epp#serverDeleteProhibited)'], 'emails': ['abusecomplaints@markmonitor.com', 'whoisrelay@markmonitor.com'], 'dnssec': 'unsigned', 'name': None, 'org': 'Beijing Baidu Netcom Science Technology Co., Ltd.', 'address': None, 'city': None, 'state': 'Beijing', 'zipcode': None, 'country': 'CN'}robotparser:解析robots.txt的工具。
1
2
3
4
5
6
7
8
9
10>>> from urllib import robotparser
>>> parser = robotparser.RobotFileParser()
>>> parser.set_url('https://www.taobao.com/robots.txt')
>>> parser.read()
>>> parser.can_fetch('Hellokitty', 'http://www.taobao.com/article')
False
>>> parser.can_fetch('Baiduspider', 'http://www.taobao.com/article')
True
>>> parser.can_fetch('Baiduspider', 'http://www.taobao.com/product')
False
一个简单的爬虫
一个基本的爬虫通常分为数据采集(网页下载)、数据处理(网页解析)和数据存储(将有用的信息持久化)三个部分的内容,当然更为高级的爬虫在数据采集和处理时会使用并发编程或分布式技术,这就需要有调度器(安排线程或进程执行对应的任务)、后台管理程序(监控爬虫的工作状态以及检查数据抓取的结果)等的参与。
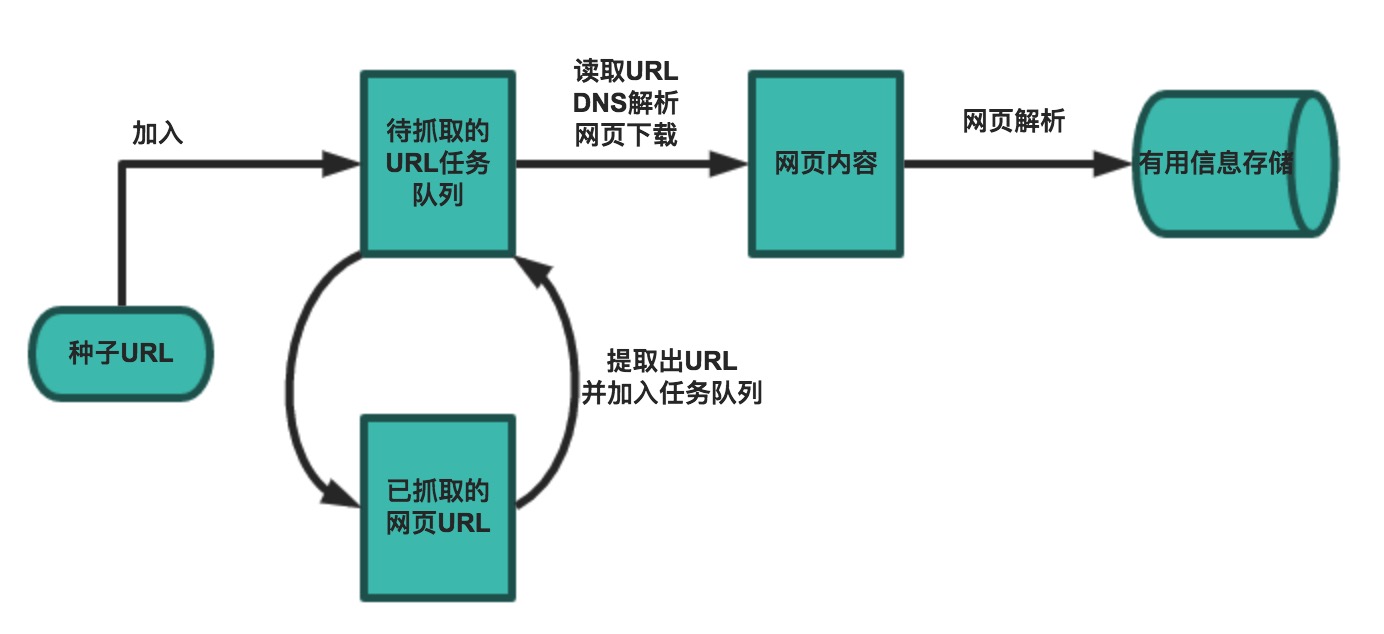
一般来说,爬虫的工作流程包括以下几个步骤:
- 设定抓取目标(种子页面/起始页面)并获取网页。
- 当服务器无法访问时,按照指定的重试次数尝试重新下载页面。
- 在需要的时候设置用户代理或隐藏真实IP,否则可能无法访问页面。
- 对获取的页面进行必要的解码操作然后抓取出需要的信息。
- 在获取的页面中通过某种方式(如正则表达式)抽取出页面中的链接信息。
- 对链接进行进一步的处理(获取页面并重复上面的动作)。
- 将有用的信息进行持久化以备后续的处理。
下面的例子给出了一个从“搜狐体育”上获取NBA新闻标题和链接的爬虫。
1 | from urllib.error import URLError |
由于使用了MySQL实现持久化操作,所以要先启动MySQL服务器再运行该程序。
爬虫注意事项
通过上面的例子,我们对爬虫已经有了一个感性的认识,在编写爬虫时有以下一些注意事项:
处理相对链接。有的时候我们从页面中获取的链接不是一个完整的绝对链接而是一个相对链接,这种情况下需要将其与URL前缀进行拼接(
urllib.parse中的urljoin()函数可以完成此项操作)。设置代理服务。有些网站会限制访问的区域(例如美国的Netflix屏蔽了很多国家的访问),有些爬虫需要隐藏自己的身份,在这种情况下可以设置使用代理服务器,代理服务器有免费(如西刺代理、快代理)和付费两种(如讯代理、阿布云代理),付费的一般稳定性和可用性都更好,可以通过
urllib.request中的ProxyHandler来为请求设置代理。限制下载速度。如果我们的爬虫获取网页的速度过快,可能就会面临被封禁或者产生“损害动产”的风险(这个可能会导致吃官司且败诉),可以在两次下载之间添加延时从而对爬虫进行限速。
避免爬虫陷阱。有些网站会动态生成页面内容,这会导致产生无限多的页面(例如在线万年历通常会有无穷无尽的链接)。可以通过记录到达当前页面经过了多少个链接(链接深度)来解决该问题,当达到事先设定的最大深度时爬虫就不再像队列中添加该网页中的链接了。
SSL相关问题。在使用
urlopen打开一个HTTPS链接时会验证一次SSL证书,如果不做出处理会产生错误提示“SSL: CERTIFICATE_VERIFY_FAILED”,可以通过以下两种方式加以解决:使用未经验证的上下文
1
2
3
4
5import ssl
request = urllib.request.Request(url='...', headers={...})
context = ssl._create_unverified_context()
web_page = urllib.request.urlopen(request, context=context)设置全局的取消证书验证
1
2
3import ssl
ssl._create_default_https_context = ssl._create_unverified_context
2、前言
2.1 数据分析
爬取网页信息可以使用很多的技术:
获取网页信息:urllib、urllib3、requests
1
2
3requests为第三方的库,需要安装才能使用
pip install requests解析网页信息:beautifulsoup4(bs4)、re、xpath、lxml
1
2
3
4
5bs4为第三方的库,需要安装才能使用
pip install beautifulsoup4
使用的时候 from bs4 import BeautifulSoup 这样导入Python 标准库中自带了 xml 模块,但是性能不够好,而且缺乏一些人性化的 API,相比之下,第三方库 lxml 是用 Cython 实现的,而且增加了很多实用的功能。
1
2
3
4
5安装lxml,在新版本中无法使用from lxml import etree
pip install lxml 并不推荐这样去安装lxml
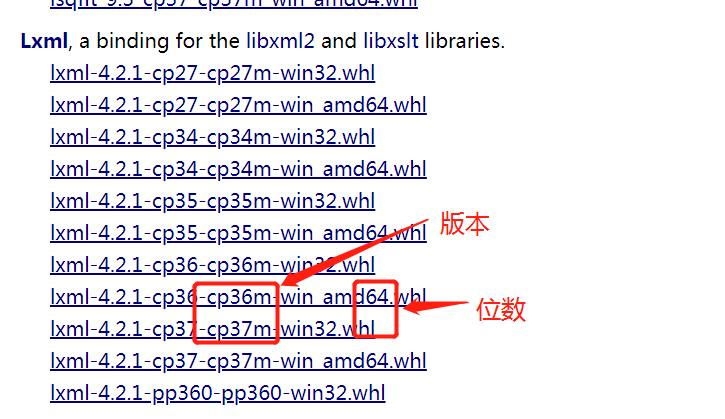
推荐安装的方法:访问网站(https://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml)下载lxml的安装whl文件,然后进行安装。注意:下载文件必须与python版本号、位数一致
我这儿下载的是lxml-4.2.1-cp36-cp36m-win_amd64.whl,安装命令如下
1 | pip install lxml-4.2.1-cp36-cp36m-win_amd64.whl |
截图:
动态数据解析
通用:selenium(自动化测试框架)
2.2 请求头分析
1 | # 浏览器告诉服务器可以接收的文本类型, */*表示任何类型都可以接收 |
其中在爬虫中最重要的就是User-Agent:在下面urllib的使用中就会详细的解释User-Agent的使用
2.3 urllib的使用
使用urllib来获取百度首页的源码
1 | import urllib.request |
按照我们的想法来说,输出的结果应该是百度首页的源码才对,但是输出却不对(多请求几次,就会出现如下的结果),如下结果:
1 | <html> |
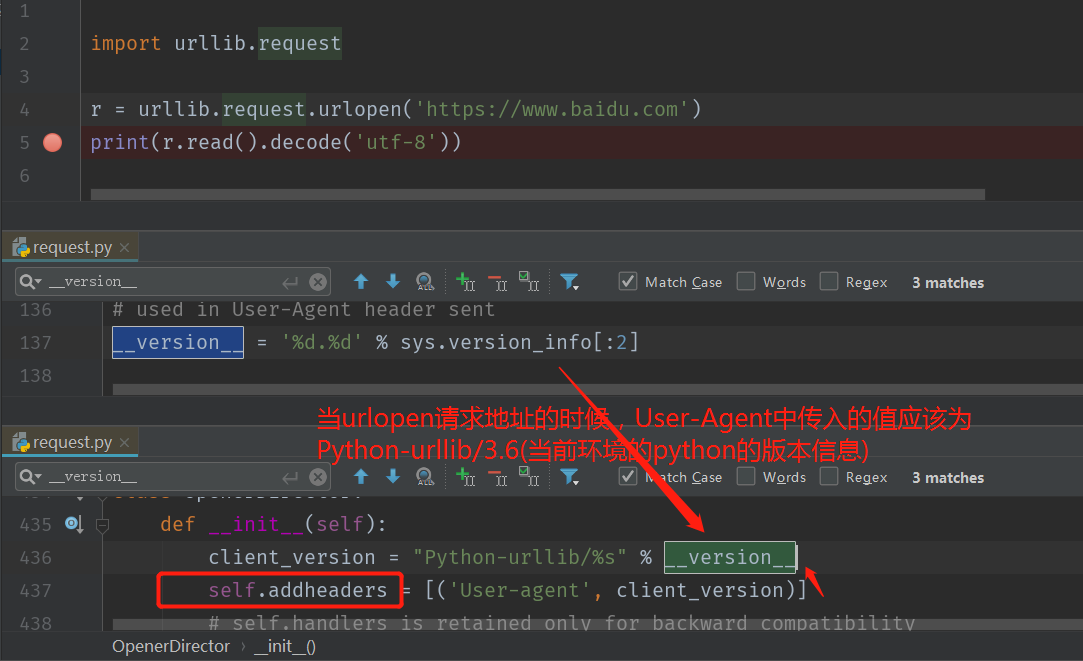
以上的结果并不是我们想要的,我们可以来查看一下为什么会出现这种问题的原因。我们可以想到刚才说的,请求头中的最重要的参数User-Agent参数,该参数是用来告诉服务器,请求的url是来源于哪儿的,是来源于浏览器还是来源于其他地方的。如果是来源于非浏览器的会就不会返回源码信息给你的,直接拦截掉你的请求
分析以上代码中,默认提交的请求头中的User-Agent到底传递了什么值:
接下来,就是优化以上的代码,实现目的就是告诉服务器我们这个请求是来源于浏览器的。
1 | header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/65.0.3325.181 Safari/537.36'} |
按照这样去解析,就可以获取到百度的首页源代码了,展示部门代码如下:
1 | <html> |
2.4 requests
安装
1 | pip install requests |
发送请求,GET、POST、PUT、PATCH、DELETE
使用请求发送网络请求非常简单。
一开始要导入请求模块:
1 | import requests |
然后,尝试获取某个网页。本例子中,我们来获取Github的公共时间线:
1 | r = requests.get('https://api.github.com/events') |
请求简便的API意味着所有HTTP请求类型都是显而易见的。例如,你可以这样发送一个HTTP POST请求:
1 | r = requests.post('http://httpbin.org/post', data = {'key':'value'}) |
传递URL参数
你也许经常想为URL的查询字符串(query string)传递某种数据。如果你是手工构造URL,那么数据会以键/值对的形式置于URL中,跟在一个问号的后面。例如, httpbin.org/get?key=val。
请求允许你使用params关键字参数,以一个字符串字典来提供这些参数。
举例来说,如果你想传递key1 = value1和key2 = value2到httpbin.org/get,那么你可以使用如下代码:
1 | payload = {'key1': 'value1', 'key2': 'value2'} |
通过打印输出该URL,你能看到URL已被正确确认编码:
1 | print(r.url) |
注意字典里值为无的键都不会被添加到URL的查询字符串里。
你还可以将一个列表作为值传入:
1 | payload = {'key1': 'value1', 'key2': ['value2', 'value3']} |
响应内容
我们能读取服务器响应的内容。再次以GitHub时间线为例:
1 | import requests |
请求会自动解码来自服务器的内容。大多数unicode字符集都能被无缝地解码。
请求发出后,请求会基于HTTP头部对响应的编码作出有根据的推测。当你访问r.text之时,请求会使用其推测的文本编码。你可以找出请求使用了什么编码,并且能够使用r.encoding属性来改变它:
1 | r.encoding |
如果你改变了编码,每当你访问r.text,请求都将会使用r.encoding的新值。你可能希望在使用特殊逻辑计算出文本的编码的情况下来修改编码。比如HTTP和XML自身可以指定编码。这样的话,你应该使用r.content来找到编码,然后设置r.encoding为相应的编码。这样就能使用正确的编码解析r.text了。
在你需要的情况下,请求也可以使用定制的编码。如果你创建了自己的编码,并使用编解码器模块进行注册,你就可以轻松地使用这个解码器名称作为r.encoding的值,然后由Requests来为你处理编码
2.5 ssl认证
什么是 SSL 证书?
SSL 证书就是遵守 SSL 安全套接层协议的服务器数字证书。
而 SSL 安全协议最初是由美国网景 Netscape Communication 公司设计开发的,全称为:安全套接层协议 (Secure Sockets Layer) , 它指定了在应用程序协议 ( 如 HTTP 、 Telnet 、 FTP) 和 TCP/IP 之间提供数据安全性分层的机制,它是在传输通信协议 (TCP/IP) 上实现的一种安全协议,采用公开密钥技术,它为 TCP/IP 连接提供数据加密、服务器认证、消息完整性以及可选的客户机认证。由于此协议很好地解决了互联网明文传输的不安全问题,很快得到了业界的支持,并已经成为国际标准。
SSL 证书由浏览器中“受信任的根证书颁发机构”在验证服务器身份后颁发,具有网站身份验证和加密传输双重功能。
如果能使用 https:// 来访问某个网站,就表示此网站是部署了SSL证书。一般来讲,如果此网站部署了SSL证书,则在需要加密的页面会自动从 http:// 变为 https:// ,如果没有变,你认为此页面应该加密,您也可以尝试直接手动在浏览器地址栏的http后面加上一个英文字母“ s ”后回车,如果能正常访问并出现安全锁,则表明此网站实际上是部署了SSL证书,只是此页面没有做 https:// 链接;如果不能访问,则表明此网站没有部署 SSL证书。
案例:
访问加密的12306的网站
如果不忽略ssl的安全认证的话,网页的源码会提示ssl认证问题,需要提供ssl认证。我们在做爬虫的时候,自动设置忽略掉ssl认证即可。代码如下:
1 | import ssl |
3、数据采集和解析
通过《网络爬虫和相关工具》一文,我们已经了解到了开发一个爬虫需要做的工作以及一些常见的问题,至此我们可以对爬虫开发需要做的工作以及相关的技术做一个简单的汇总,这其中可能会有一些我们之前没有使用过的第三方库。
- 下载数据 - urllib / requests / aiohttp。
- 解析数据 - re / lxml / beautifulsoup4(bs4)/ pyquery。
- 缓存和持久化 - pymysql / sqlalchemy / peewee/ redis / pymongo。
- 生成数字签名 - hashlib。
- 序列化和压缩 - pickle / json / zlib。
- 调度器 - 进程(multiprocessing) / 线程(threading) / 协程(coroutine)。
四种采集方式
四种采集方式的比较
| 抓取方法 | 速度 | 使用难度 | 备注 |
|---|---|---|---|
| 正则表达式 | 快 | 困难 | 常用正则表达式 在线正则表达式测试 |
| lxml | 快 | 一般 | 需要安装C语言依赖库 唯一支持XML的解析器 |
| Beautiful | 较快/较慢(取决于解析器) | 简单 | |
| PyQuery | 较快 | 简单 | Python版的jQuery |
说明:Beautiful的解析器包括:Python标准库(html.parser)、lxml的HTML解析器、lxml的XML解析器和html5lib。
正则表达式
如果你对正则表达式没有任何的概念,那么推荐先阅读《正则表达式30分钟入门教程》,然后再阅读我们之前讲解在Python中如何使用正则表达式一文。
re正则匹配
匹配规则:(原始字符串’booby123’)
1 | ^ 开头 '^b.*'----以b开头的任意字符 |
XPath语法与Lxml库
XPATH 术语
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
请看下面这个 XML 文档:
1 | <?xml version="1.0" encoding="ISO-8859-1"?> |
上面的XML文档中的节点例子:
1 | <bookstore> (文档节点) |
节点关系
父(Parent)、子(Children) 每个元素以及属性都有一个父。
例子:
1 | <bookstore> |
book 元素是 title、author、year 以及 price 元素的父
title、author、year 以及 price 元素都是 book 元素的子
title、author、year 以及 price 元素都是同胞:
title 元素的先辈是 book 元素和 bookstore 元素
bookstore 的后代是 book、title、author、year 以及 price 元素
选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
爬取搜狐体育:
1 | import re |
BeautifulSoup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.——-引入官网地址的一句话
安装
Beautiful Soup 4 通过PyPi发布,所以如果你无法使用系统包管理安装,那么也可以通过 easy_install 或 pip 来安装.包的名字是 beautifulsoup4 ,这个包兼容Python2和Python3.
1 | pip install beautifulsoup4 |
创建 Beautiful Soup 对象
1 | from bs4 import BeautifulSoup # 首先必须要导入 bs4 库 |
解析语法、find、find_all
find_all( name , attrs , recursive , text , kwargs )**
find_all() 方法搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件
1 | 1. 查询所有a标签的内容 |
PyQuery
pyquery相当于jQuery的Python实现,可以用于解析HTML网页。
- 存储:mysql、redis、mongodb、sqlalchemy
- 序列化:json
- 调度器:进程、线程、协程
PyQuery的基本使用
1.安装方法
1 | pip install pyquery |
2.引用方法
1 | from pyquery import PyQuery as pq |
3.简介
pyquery 是类型jquery 的一个专供python使用的html解析的库,使用方法类似bs4。
4.使用方法
4.1 初始化方法:
1 | from pyquery import PyQuery as pq |
4.2 基本CSS选择器
1 | from pyquery import PyQuery as pq |
运行结果:
1 | <link href="http://asda.com">asdadasdad12312</link> |
#是查找id的标签 .是查找class 的标签 link 是查找link 标签 中间的空格表示里层(注意层级关系以空格隔开)
4.3 查找子元素
1 | from pyquery import PyQuery as pq |
运行结果:
1 | <div id="wrap"> |
根据运行结果可以发现返回结果类型为pyquery,并且find方法和children 方法都可以获取里层标签
4.4查找父元素
1 | doc = pq(html) |
parent可以查找出外层标签包括的内容,与之类似的还有parents,可以获取所有外层节点
4.5 查找兄弟元素
1 | doc = pq(html) |
根据运行结果可以看出,siblings 返回了同级的其他标签
结论:子元素查找,父元素查找,兄弟元素查找,这些方法返回的结果类型都是pyquery类型,可以针对结果再次进行选择
4.6 遍历查找结果
1 | doc = pq(html) |
运行结果:
1 | <link class="active1 a123" href="http://asda.com">asdadasdad12312</link> |
4.7获取属性信息
1 | doc = pq(html) |
4.8 获取文本
1 | doc = pq(html) |
4.9 获取 HTML信息
1 | doc = pq(html) |
运行结果:
1 | <a>asdadasdad12312</a> |
5.常用DOM操作
5.1 addClass removeClass
添加,移除class标签
1 | doc = pq(html) |
需要注意的是已经存在的class标签不会继续添加
5.2 attr css
attr 为获取/修改属性 css 添加style属性
1 | doc = pq(html) |
attr css操作直接修改对象的
5.3 remove 移除标签
1 | doc = pq(html) |
4、并发、并行、同步、异步线程、进程
4.1 同步和异步、阻塞和非阻塞
同步和异步
同步和异步是相对于操作结果来说,会不会等待结果
阻塞和非阻塞
阻塞是在煮稀饭的过程中,你不能去干其他的事情。非阻塞是在煮稀饭的过程中,你还可以去做其他的事情。阻塞和非阻塞是相对于线程是否被阻塞
同步和阻塞的区别
同步是一个过程,阻塞是线程的一个状态。
当多个线程操作同一公共变量的时候可能会出现竞争的情况,这时候需要使用同步来防止多个线程同时占用资源的情况,让一个线程在运行状态中,另外的线程处于就绪状态,当前一个线程处于暂停状态的时候,后面的处于就绪状态的线程,获取到资源以后,获取到时间片以后就会处于运行状态了。所以阻塞是线程的一个状态而已
并发和并行
并发:从点餐系统看,该肯德基店只有一个负责点餐的收银员,而有2台收银点餐设备,服务员同时操作2个收银点餐终端,这叫并发操作收银点餐终端。
并行:肯德基为了拓展业务,提高同时服务的能力,在全世界开设分店,这叫并行。
如何实现并发呢:需要引入多进程,多线程,协程
4.2 进程
概念:
进程即正在执行的一个过程。进程是对正在运行程序的一个抽象。操作系统以进程为单位分配存储空间,每个进程都有自己的地址空间、数据栈以及其他用于跟踪进程执行的辅助数据,操作系统管理所有进程的执行,为它们合理的分配资源。进程可以通过fork或spawn的方式来创建新的进程来执行其他的任务,不过新的进程也有自己独立的内存空间,因此必须通过进程间通信机制(IPC,Inter-Process Communication)来实现数据共享,具体的方式包括管道、信号、套接字、共享内存区等。
python实现进程:
multiprocessing模块就是跨平台版本的多进程模块。
multiprocessing模块提供了一个Process类来代表一个进程对象,
代码:
1 | import os |
杀掉进程
按照上面案例代码运行的话,p1进程会一直阻塞,后面的p2和p3并不会执行。如果在windows中运行的代码,则直接运行‘启动任务管理器’去杀掉进程,这时候p2和p3的进程就会执行了,说明进程之间是相互没有关联的,互不影响的。如果在linux系统中,直接kill -9 PID,就可以杀掉进程了
4.3 线程
一个进程中的多个线程可以共享一个资源内存空间
Python的标准库提供了两个模块:thread和threading,thread是低级模块,threading是高级模块,对thread进行了封装。绝大多数情况下,我们只需要使用threading这个高级模块。
启动一个线程,创建threading的实例,然后直接start()就可以启动我们定义的线程了。
多线程
定义一个线程类,继承自threading.Thread
其中打印一下当前线程的名称,使用threading.current_thread().name来获取当前线程的名称。默认的Python就自动给线程命名为Thread-1,Thread-2……。当然我们也可以自定义线程的名称
1 | import threading |
启动一个线程:
1 | thread1 = DataCopy('database1') |
运行结果:

守护线程
当定义子线程为守护线程的话,当主线程结束了,不管子线程是否执行完,都会被直接给暂停掉。默认daemon为False
代码:
1 | thread1 = DataCopy('database1') |
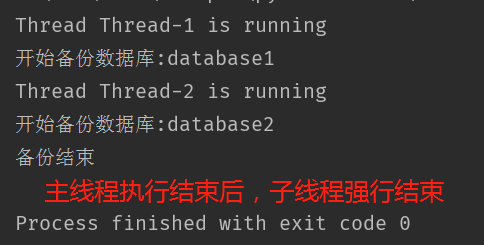
线程启动
解释: start和run的区别
start() 方法是启动一个子线程,线程名就是我们定义的name,或者默认的线程名Thread-1, Thread-2……
run() 方法并不启动一个新线程,就是在主线程中调用了一个普通函数而已。
代码1,先使用start()启动线程,并且打印当前线程的名称:
1 | thread1 = DataCopy('database1') |
运行结果:
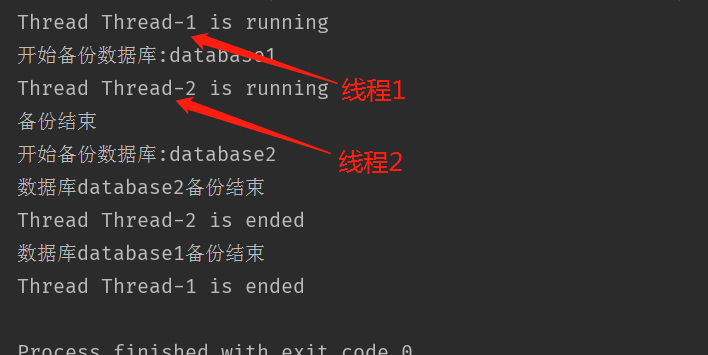
代码2,使用run()启动线程,并且打印当前线程的名称:
1 | thread1 = DataCopy('database1') |
运行结果:
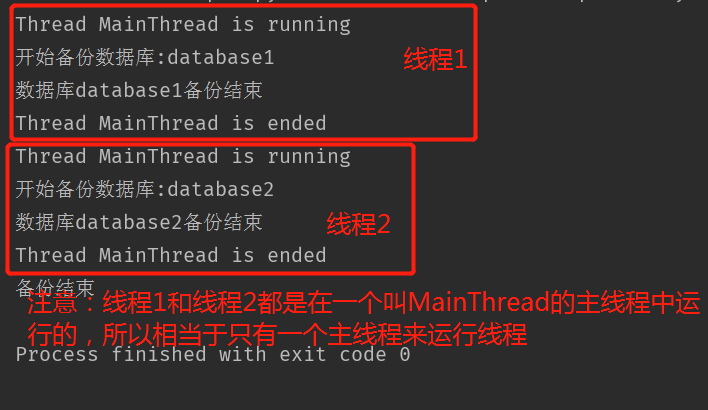
4.4 线程锁
使用线程时最不愿意遇到的情况就是多个线程竞争资源,在这种情况下为了保证资源状态的正确性,我们可能需要对资源进行加锁保护的处理,这一方面会导致程序失去并发性,另外如果多个线程竞争多个资源时,还有可能因为加锁方式的不当导致死锁。
要实现将资源和持有资源的线程进行绑定的操作,最简单的做法就是使用threading模块的local类,在网络爬虫开发中,就可以使用local类为每个线程绑定一个MySQL数据库连接或Redis客户端对象,这样通过线程可以直接获得这些资源,既解决了资源竞争的问题,又避免了在函数和方法调用时传递这些资源。
锁的概念
线程锁:其实并不是给资源加锁, 而是用锁去锁定资源,你可以定义多个锁,当你需要独占某一资源时,任何一个锁都可以锁这个资源,就好比你用不同的锁都可以把相同的一个门锁住是一个道理
基本语法:
1 | #创建锁 |
代码:怎么使用锁去锁住资源,释放锁
1 | import threading |
以上代码,只是教会你怎么去使用锁,锁住资源,当一个线程在使用锁住的资源的时候,其他线程则无法再使用该资源了,起到了很好的避免资源的竞争。
多线程去打印输出自增的全局变量
定义一个简单的多线程,主要功能是用于打印全局递增的变量参数,并打印线程名。
可以不妨想想,如果启动多线程对同一全局变量进行递增操作的话,就有可能多个线程同时获取到全局变量,然后进行递增操作。可想而知,如果是这样的话,那么打印出来的变量就有可能会重复。这就是出现了一个进程中,多线程同时共享一个资源的时候,出现的资源竞争的问题了。我们先查看一下代码的运行结果,然后进行分析:
1 | import threading |
运行结果:
1 | 1 Thread-2 |
分析:
很明显的在我们的执行结果中,打印的全局变量n中有很多重复的,这就印证了我们的多线程在共享资源上存在不可避免的资源竞争的关系。为了解决这种资源的竞争,我们可以采取线程锁的形式去避免对资源的竞争
优化多线程打印输出自增的全局变量
代码优化:
1 | def run(self): |
运行结果:
1 | 1 Thread-2 |
分析:在优化的代码中,我们先建立了一个threading.Lock类对象lock,在run方法里,我们使用lock.acquire()获得了这个锁。此时,其他的线程就无法再获得该锁了,他们就会阻塞在“if lock.acquire()”这里,直到锁被另一个线程释放:lock.release()。所以,if语句中的内容就是一块完整的代码,不会再存在执行了一半就暂停去执行别的线程的情况。所以最后结果是整齐的。完美的解决了多线程竞争同一资源造成的问题了。
5、异步I/O
协程的概念
协程(coroutine)通常又称之为微线程或纤程,它是相互协作的一组子程序(函数)。所谓相互协作指的是在执行函数A时,可以随时中断去执行函数B,然后又中断继续执行函数A。注意,这一过程并不是函数调用(因为没有调用语句),整个过程看似像多线程,然而协程只有一个线程执行。协程通过yield关键字和 send()操作来转移执行权,协程之间不是调用者与被调用者的关系。
协程的优势在于以下两点:
- 执行效率极高,因为子程序(函数)切换不是线程切换,由程序自身控制,没有切换线程的开销。
- 不需要多线程的锁机制,因为只有一个线程,也不存在竞争资源的问题,当然也就不需要对资源加锁保护,因此执行效率高很多。
说明:协程适合处理的是I/O密集型任务,处理CPU密集型任务并不是它的长处,如果要提升CPU的利用率可以考虑“多进程+协程”的模式。
历史回顾
- Python 2.2:第一次提出了生成器(最初称之为迭代器)的概念(PEP 255)。
- Python 2.5:引入了将对象发送回暂停了的生成器这一特性即生成器的
send()方法(PEP 342)。 - Python 3.3:添加了
yield from特性,允许从迭代器中返回任何值(注意生成器本身也是迭代器),这样我们就可以串联生成器并且重构出更好的生成器。 - Python 3.4:引入
asyncio.coroutine装饰器用来标记作为协程的函数,协程函数和asyncio及其事件循环一起使用,来实现异步I/O操作。 - Python 3.5:引入了
async和await,可以使用async def来定义一个协程函数,这个函数中不能包含任何形式的yield语句,但是可以使用return或await从协程中返回值。
在将协程的时候,需要分别引入迭代器和生成器的含义以及案例
迭代器
迭代器和生成器都是python中最重要的知识点。迭代器可以遍历整个对象,在你需要取值的时候,调用next就可以依次获取迭代器中的下一个值,在迭代中中只能往下取值,不能再往上取值的
案例代码:
声明一个列表[1,2,3,4],然后使用iter()去创建一个迭代器,然后依次调用next()就可以获取到迭代器中的下一个值了
1 | s = iter([1, 2, 3, 4]) |
运行结果:
1 | <class 'list'> |
生成器
什么是生成器:使用了 yield 的函数被称为生成器(generator)。生成器函数返回的结果就是一个迭代器,只能用于迭代操作。既然是迭代器了,就有next()的属性了。
那生成器是怎么工作的呢:在调用生成器运行的过程中,当在第一次运行的时候,在遇到yield时函数会暂停并保持当前所有的运行信息,返回一个yield的值,当再次next()的时候,才会在当前代码位置进行运行。
案例代码: 实现斐波那契算法 0 1 1 2 3 5 8 13 21 34 55
1 | import sys |
运行结果为:
1 | 0 1 1 2 3 5 8 13 21 34 55 |
执行线路图:
查看执行的流程可以使用debug模式去运行,通过断点调试可以很清晰的了解到整个代码的运行流程。
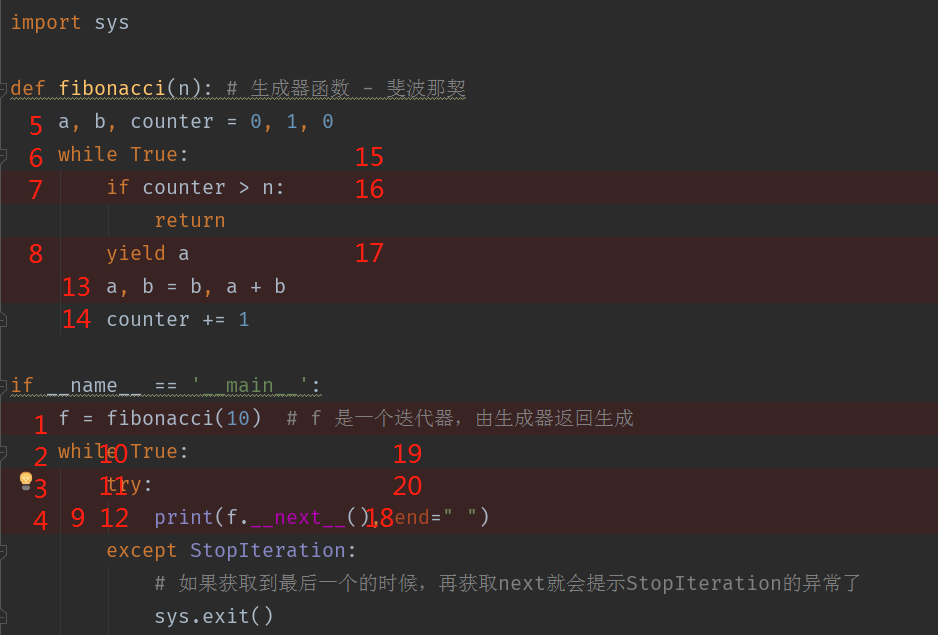
协程例子
案例代码: 消费者和生产者模式
1 | import time |
运行结果:
1 | 开始协程 |
代码分析:
在获取迭代器的时候,有三种获取方式
next(customer)
customer.send(None)
customer.next()
注意:
1 | customer函数是一个generator(生成器),把一个customer传入produce后: |
重点:区分next()和send()的区别
其实next()和send()在一定意义上作用是相似的,区别是send()可以传递yield表达式的值进去,而next()不能传递特定的值,只能传递None进去。因此,我们可以看做next() 和 send(None) 作用是一样的。需要提醒的是,第一次调用时,请使用next()语句或是send(None),不能使用send发送一个非None的值,否则会直接报错
aiohttp
aiohttp是什么,官网上有这样一句话介绍:Async HTTP client/server for asyncio and Python,是异步的HTTP框架
安装
1 | pip install aiohttp |
爬取豆瓣电影资源
1 | import aiohttp |
6、数据持久化
1.Redis介绍
Redis是REmote DIctionary Server的缩写,它是一个用ANSI C编写的高性能的key-value存储系统,与其他的key-value存储系统相比,Redis有以下一些特点(也是优点):
- 的Redis的读写性能极高,并且有丰富的特性(发布/订阅,事务,通知等)。
- Redis的支持数据的持久化(RDB和AOF两种方式),可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis的不仅仅支持简单的键 - 值类型的数据,同时还提供哈希,列表,设置,zset,hyperloglog,地理等数据类型。
- Redis的支持主从复制(实现读写分析)以及哨兵模式(监控主是否宕机并调整配置)。
Redis的在CentOS的中的安装配置已经上章文章中已经整理好了,如需查看自行跳转过去查看,地址 .Redis有着非常丰富的数据类型,也有很多的命令来操作这些数据,具体的内容可以查看Redis的命令参考,在这个网站上,除了Redis的的命令参考,还有Redis的的详细文档,其中包括了通知,事务,主从复制,持久化,哨兵,集群等内容。
在Python程序中使用Redis
可以使用画中画安装Redis的模块.redis模块的核心是名为Redis的的类,该类的对象代表一个Redis的客户端,通过该客户端可以向Redis的服务器发送命令并获取执行的结果。我们在Redis的客户端中使用的命令基本上就是Redis的对象可以接收的消息。
首先:安装的Redis
1 | pip3 install redis |
简单案例
该案例:用户在登录的时候,先验证传入的用户名和密码是否在Redis的中,是否能验证通过,如果不能验证通过的话,就去MySQL的数据库中验证,如果验证成功则同步的Redis中用户的信息。
1 | # -*- coding:utf-8 -*- |
2. mongodb介绍
MongoDB的是2009年年问世的一个面向文档的数据库管理系统,由C ++语言编写,旨在为网络应用提供可扩展的高性能数据存储解决方案。虽然在划分类别的时候后,MongoDB的被认为是的NoSQL的产品,但是它更像一个介于关系数据库和非关系数据库之间的产品,在非关系数据库中它功能最丰富,最像关系数据库。
MongoDB的将数据存储为一个文档,一个文档由一系列的“键值对”组成,其文档类似于JSON对象,但是MongoDB的对JSON进行了二进制处理(能够更快的定位键和值),因此其文档的存储格式称为BSON。关于JSON和BSON的差别大家可以看看MongoDB官方网站的文章“JSON和BSON”。
目前,MongoDB中已经提供了对Windows中的MacOS,Linux和Solaris等多个平台的支持,而且也提供了多种开发语言的驱动程序,Python的当然是其中之一。
MongoDB中安装的配置以及语法操作都整理好了,可以自行前往回顾,熟悉语法。
在python中操作mongodb
通过PIP安装pymongo来实现对MongoDB中的操作。
1 | pip install pymongo |
简单的访问蒙戈,并打印文档中的信息
1 | from pymongo import MongoClient |
7、动态解析
根据权威机构发布的全球互联网可访问性审计报告,全球约有四分之三的网站其内容或部分内容是通过JavaScript动态生成的,这就意味着在浏览器窗口中“查看网页源代码”时无法在HTML代码中找到这些内容,也就是说我们之前用的抓取数据的方式无法正常运转了。解决这样的问题基本上有两种方案:
一是JavaScript逆向工程;
另一种是渲染JavaScript获得渲染后的内容。
JavaScript逆向工程
我们以豆瓣电影为例,说明什么是JavaScript逆向工程。其实所谓的JavaScript逆向工程就是找到通过Ajax请求动态获取数据的接口。
但是当我们在浏览器中通过右键菜单“显示网页源代码”的时候,居然惊奇的发现页面的HTML代码中连一个电影的名称都搜索不到。
那网页中的数据到底是怎么加载出来的呢,其实网页中的数据就是一个动态加载出来的。可以在浏览器的“开发人员工具”的“网络”中可以找到获取这些图片数据的网络API接口,如下图所示。
那么结论就很简单了,只要我们找到了这些网络API接口,那么就能通过这些接口获取到数据,当然实际开发的时候可能还要对这些接口的参数以及接口返回的数据进行分析,了解每个参数的意义以及返回的JSON数据的格式,这样才能在我们的爬虫中使用这些数据。
selenium自动框架
使用自动化测试工具Selenium,它提供了浏览器自动化的API接口,这样就可以通过操控浏览器来获取动态内容。首先可以使用pip来安装Selenium。
安装
1 | pip install selenium |
使用
我们通过Selenium实现对Chrome浏览器的操控,如果要操控其他的浏览器,可以创对应的浏览器对象,例如Chrome、Firefox、Edge等,还有手机端的浏览器Android、BlackBerry等,另外无界面浏览器PhantomJS也同样支持。
1 | from selenium import webdriver |
这样我们就完成了一个浏览器对象的初始化,接下来我们要做的就是调用browser对象,让其执行各个动作,就可以模拟浏览器操作了。
案例中我们使用Chrome浏览器,在模拟Chrome浏览器的时候,如果报如下的错误的话,说明你没有Chrome的驱动。接下来就是添加Chrome的驱动到我们的环境变频path中,或者在程序中指定Chrome驱动的位置
1 | selenium.common.exceptions.WebDriverException: Message: 'chromedriver' executable needs to be in PATH. Please see https://sites.google.com/a/chromium.org/chromedriver/home |
驱动已经下载好了,保存地址在(spider/chromedriver_win32/)中
访问url
可以用get()方法来请求一个网页,参数传入链接URL即可
获取元素
在浏览器中的操作,都可以通过selenium来完成,比如填充表单,模拟点击等等。那我们在进行这些操作的时候,首先需要知道我们要填充表单的位置在哪儿,模拟点击的按钮在哪儿。那怎么去获取这些信息呢。selenium中获取元素的方法有很多。
获取单个元素
大概解释一下如下用法:
find_element_by_name()是根据Name值获取
ind_element_by_id()是根据ID获取
find_element_by_xpath()是根据Xpath提取
find_element_by_css_selector(‘#xxx’)是根据id=xxx来获取
find_element()方法,它需要传入两个参数,一个是查找的方式By,另一个就是值,实际上它就是find_element_by_id()这种方法的通用函数版本。
注意: from selenium.webdriver.common.by import By
1 | find_element_by_id(id) |
获取多个元素
find_elements_by_css_selector(‘#xxx li’)是根据id=xxx来获取下面的所有li的结果
查找淘宝导航条的所有条目
案例代码:
1 | from selenium import webdriver |
延时等待
在Selenium中,get()方法会在网页框架加载结束之后就结束执行,此时如果获取page_source可能并不是浏览器完全加载完成的页面,如果某些页面有额外的Ajax请求,我们在网页源代码中也不一定能成功获取到。所以这里我们需要延时等待一定时间确保元素已经加载出来。在这里等待的方式有两种,一种隐式等待,一种显式等待。
以访问知乎发现页面为案例:
1 | from selenium import webdriver |
前进后退
使用back()方法可以后退,forward()方法可以前进
1 | browser.back() |
Cookies操作
1 | from selenium import webdriver |
切换窗口
以淘宝为例:
打开浏览器在主页中点击女装案例,再切换回主页再点击男装按钮,然后主页进行back()和froward()操作,最后退出整个浏览器quit()
1 | import time |
获取一共启动了多少窗口:
1 | browser.window_handles |
8、scrapy框架
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据或者通用的网络爬虫。
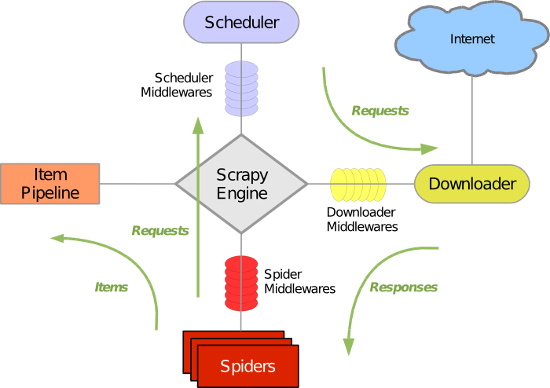
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下:
初窥Scrapy
1. 安装
1 | pip install Scrapy |
安装过程中会安装如下一些包,在之前的安装过程中,偶尔会出现Twisted失败的话,需要自己手动去安装。

在此也先安装另外一个必备的包pywin32,如果不安装该包的话,在运行爬虫的时候可能会提示“ModuleNotFoundError: No module named ‘win32api’”,因为Python没有自带访问windows系统API的库的,需要下载第三方库。库的名称叫pywin32。可以去网站上下载,下载地址
按照自己电脑上的python版本,进行下载安装。安装的时候,先进入虚拟环境中,然后执行easy_install pywin32-221.win-amd64-py3.6.exe 命令即可将包安装在我们当前的虚拟环境中了。

2. Scrapy组件
1. 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心)
2. 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列,
由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
3. 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
4. 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
5. 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,
将被发送到项目管道,并经过几个特定的次序处理数据。
6. 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
7. 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
8. 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
3. 处理流程
Scrapy的整个数据处理流程由Scrapy引擎进行控制,通常的运转流程包括以下的步骤:
- 引擎询问蜘蛛需要处理哪个网站,并让蜘蛛将第一个需要处理的URL交给它。
- 引擎让调度器将需要处理的URL放在队列中。
- 引擎从调度那获取接下来进行爬取的页面。
- 调度将下一个爬取的URL返回给引擎,引擎将它通过下载中间件发送到下载器。
- 当网页被下载器下载完成以后,响应内容通过下载中间件被发送到引擎;如果下载失败了,引擎会通知调度器记录这个URL,待会再重新下载。
- 引擎收到下载器的响应并将它通过蜘蛛中间件发送到蜘蛛进行处理。
- 蜘蛛处理响应并返回爬取到的数据条目,此外还要将需要跟进的新的URL发送给引擎。
- 引擎将抓取到的数据条目送入条目管道,把新的URL发送给调度器放入队列中。
上述操作中的2-8步会一直重复直到调度器中没有需要请求的URL,爬虫停止工作。
4. Scrapy项目
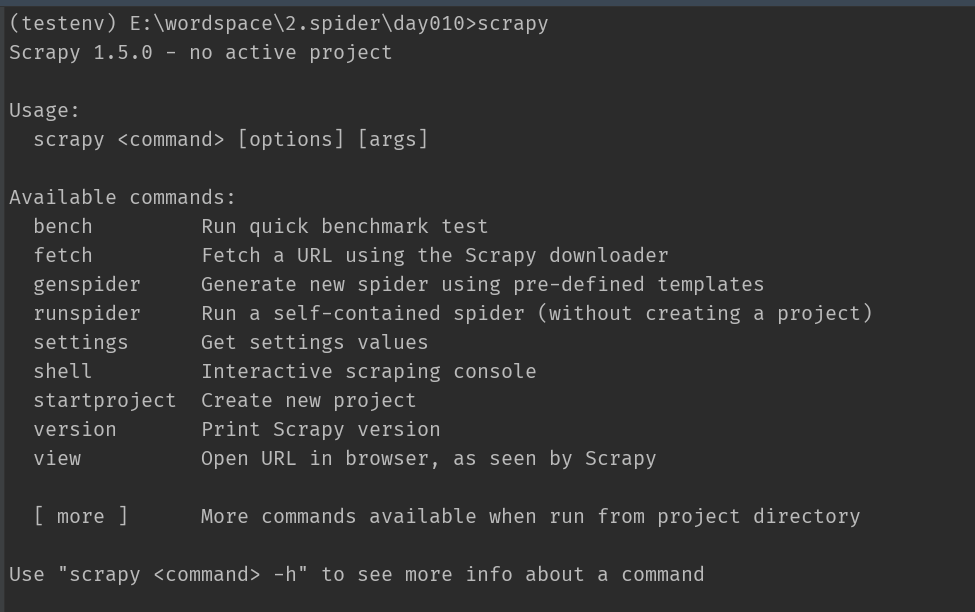
在创建项目开始,我们先确认一下之前安装的scrapy能否正常运行,如下情况即安装成功:
4.1 创建项目
1 | scrapy startproject dbspider |
创建成功以后,在我们的文件夹中会发现一个dbspider的目录,这个项目文件就是我们的爬虫项目了。可以先看看它的构成,接下来详细讲解一下每一个文件代表的意思。
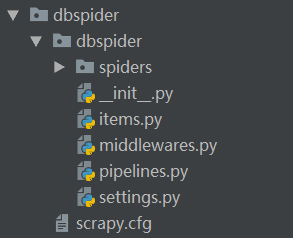
4.2 文件解释
文件说明:
scrapy.cfg:项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py:设置数据存储模板,用于结构化数据,如:Django的Model
pipelines:数据处理行为,如:一般结构化的数据持久化
settings.py:配置文件,如:递归的层数、并发数,延迟下载等
spiders:爬虫目录,如:创建文件,编写爬虫规则。
在spiders文件中创建爬虫的时候,一般以爬取的网站的域名为爬虫的名称
5. 编写爬虫
爬取起点中文网的网页源码,爬取小说分类名称以及url
案例代码:
1 | import scrapy |
class QiDianSpider(scrapy.spiders.Spider): name = “qidian” start_urls = [ “https://www.qidian.com/“, ]
1 | def parse(self, response): |
5.1 运行命令:
1 | scrapy crawl qidian |
启动命令中 ‘qidian’参数为我们定义爬虫中的name属性的值
执行流程:
name: spider对应不同的name
start_urls:是spider抓取网页的起始点,可以包括多个url。
parse():spider抓到一个网页以后默认调用的callback,避免使用这个名字来定义自己的方法。当spider拿到url的内容以后,会调用parse方法,并且传递一个response参数给它,response包含了抓到的网页的内容,在parse方法里,你可以从抓到的网页里面解析数据。
运行结果:

9、分布式爬虫
说到分布式系统的时候,要和集中式系统进行对比的学习,下面就先介绍下集中式系统,对比它们的优缺点进行学习。
集中式系统
集中式系统:
集中式系统中整个项目就是一个独立的应用,整个应用也就是整个项目,所有的业务逻辑功能都在一个应用里面。如果遇到并发的瓶颈的时候,就多增加几台服务器来部署项目,以此来解决并发分问题。在nginx中进行负载均衡即可。
缺点:
a) 不易于扩展
b) 如果发现你的项目代码中有bug的话,那么你的所有的服务器中的项目代码都是有问题的,这时候要更新这个bug的时候,就需要同时更新所有的服务器了。
优点:
维护方便
分布式系统
分布式系统:
分布式系统中,我们的整个项目可以拆分成很多业务块,每一个业务块单独进行集群的部署。这样就将整个项目分开了,在进行拓展的时候,系统是很容易横向拓展的。在并发的时候,也很好的将用户的并发量提上去。
缺点:
a) 项目拆分的过于复杂,给运维带来了很高的维护成本
b) 数据的一致性,分布式事务,分布式锁等问题不能得到很好的解决
优点:
a) 一个业务模块崩了,并不影响其他的业务
b) 利于扩展
c) 在上线某个新功能的时候,只需要新增对应的分布式的节点即可,测试也只需要测试该业务功能即可。很好的避免了测试在上线之前需要将整个系统进行全方面的测试
1. scrapy的分布式原理
我们还是先回顾下scrapy的运行原理的构造图:
该图很好的阐释了在不是scrapy的服务器中的运行结构图,在维护爬取的url队列的时候,使用scheduler进行调度的。那么如果要修改为分布式的scrapy爬虫的话,其实就是将爬取的队列进行共享,多台部署了scrapy爬虫的服务器共享该爬取队列。
2. 分布式架构:
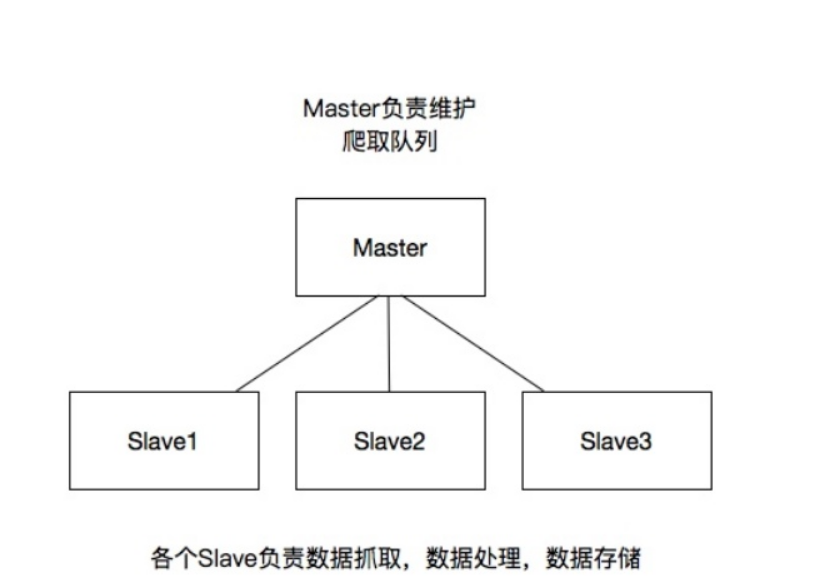
master-主机:维护爬虫队列。
slave-从机:数据爬取,数据处理,数据存储。
3. 搭建分布式爬虫
我们使用scrapy_redis进行分布式爬虫的搭建。
scrapy_redis是scrapy框架下的一个插件,通过重构调度器来使我们的爬虫运行的更快
3.1 安装
安装scrapy_redis:
1 | pip install scrapy_redis |
安装redis:
1 | # redis可以仅在master主机上安装 |
安装数据存储数据库,采用mongodb 见: 安装配置地址
3.2 redis
在维护爬虫队列的时候,很多爬虫项目同时读取队列中的信息,就造成了可能读数据重复了,比如同时读取同一个url。为了避免这种情况,我们建议使用redis去维护队列。而且redis的集合中的元素还不是重复的,可以很好的利用这一点,进行url爬取地址的存储
3.3 分布式爬虫改造
3.3.1 master
master主机改造: 在master主机上安装redis并启动,最好设置密码
spiders文件中定义的爬虫py文件修改如下:
如下爬虫实现的功能是拿到需要爬取的成都各大区县的二手房页面url地址,包括分页的地址。并将数据存储到redis中
1 | import json |
定义Item
接收一个地址url参数:
1 | class MasterItem(scrapy.Item): |
新增redis存储中间件
1 | class MasterPipeline(object): |
3.3.2 slave改造:
slave从机改造:slave从机访问redis,直接去访问master主机上的redis的地址,以及端口密码等信息
spiders爬虫文件改造
继承改为继承Redisspider
1 | from scrapy_redis.spiders import RedisSpider |
具体代码优化如下:
1 | from scrapy_redis.spiders import RedisSpider |
settings.py配置改造
新增如下的配置:
1 | # scrapy-redis |

